炙手可热的 Facebook 是用 PHP 开发的。随着一些技术交流,逐渐能看到 Facebook 技术人员分享的经验。近期这个 geekSessions 站点上看到 Facebook 的 Lucas Nealan 分享的文档比较有参考价值。
Cache 为 王
任何一个成功的站点都有一套最合适自己的 Cache 策略。

Note:这个层次图画的稍微有点问题,不是严格从上到下的。
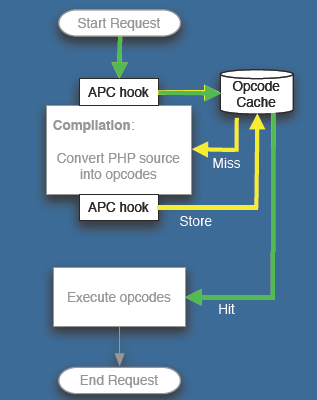
The Alternative PHP Cache , APC
Facebook 平均每个用户每天要访问超过 50 个页面,PHP的页面载入时间的优化就比较重要了。在 PHP Cache 层,Facebook 采用了 APC。
Lucas Nealan 的 PPT 举了一个例子,一个页面显示的时间从 4000 多毫秒降到了 100 多 毫秒。在 apc.stat 关闭的模式下,性能还要更好一些。不过需要重启动或用apc_cache_clear() 来通知更新。
Memcached 层
APC Cache 的是非用户相关的信息,而用户相关的数据 Cache 当然是在 Memcached 中。
Facebook 部署了超过 400 台 Memcached 服务器,超过 5TB 的数据在 Memcached 中。这是当前世界上最大的 Memcached 集群了。也给 Memcached 贡献了不少代码,包括 UDP 的支持和性能上的提升(性能提升超过 20%)。
程序 Profiling
Facebook 开发人员大量采用 Callgrind 、APD、 xdebug 、KCachegrind 等工具进行基准性能测试。任何一个 Web 项目,这也是不可或缺,也是比较容易忽略的一环。所有开发人员都应该具备熟练使用这些工具的能力才好。
补充一下:语言的选择
为什么 Facebook 选择 PHP 而不是其他语言? 用Flickr 的 Cal Henderson 这句话就能说明了: "Languages's don't Scale, Architecture Scale"。
从 80-20 的原则看,APC 和 Memcached 是最主要的。在这两个环节上下功夫,受益/开销比要大于另外几个环节。
(上面的图是从 Lucas Nealan 的文档截的,版权所有是他的)
--EOF--