按:此为客座博文系列。投稿人吴朱华,曾在IBM中国研究院从事与云计算相关的研究,现在则致力于研发下一代云计算系统,撰写一些与云计算相关的文章,他的个人站点: PeopleYun.com。(文章版权属于原作者,转载请勿混淆。本篇原文地址)
本文将首先介绍一下多租户的概念和多租户的优缺点,之后会讲解几个常见的多租户模型。
概念
虽然对我们而言,多租户(Multitenancy)可以算是一个非常新颖的概念,但是其实这个概念已经由来已久了。简单而言,多租户指得就是一个单独的软件实例可以为多个组织服务。一个支持多租户的软件需要在设计上能对它的数据和配置信息进行虚拟分区,从而使得每个使用这个软件的组织能使用到一个单独的虚拟实例,并且可以对这个虚拟实例进行定制化。但是要让一个软件支持多租户并非易事,因为不仅对它的软件架构进行相应的修改,而且需要对它的数据库结构进行特殊的设计,同时在安全和隔离性方面也要有所保障。
还有,为了帮助大家进一步理解多租户这个概念,特别选取两个和多租户比较接近的概念来进行进一步的辨析。
多租户和多用户的区别
多用户的关键点在于不同的用户拥有不同的访问权限,但是多个用户共享同一个的实例。而在多租户中,多个组织使用的实例各不相同。
多租户和虚拟化的区别
多租户和虚拟化在概念是比较类似,都是给每个用户一个虚拟的实例,并且都支持定制化,但是它们作用的层次不同:虚拟化主要是虚拟出一个操作系统的实例,而多租户则是主要虚拟出一个应用的实例。
优缺点
多租户的优点:
- 经济:因为通过一个软件实例被多个组织共享,从而减低了整体资源的消耗,也同时减低应用运行的成本和相应的管理开支。
- 易于更新和开发:因为所有组织都共享同一套核心代码,所以能够让软件更新和开发更简单。
- 管理方便:首先,通过使用了多租户架构能减少物理资源和软件资源,这将简化管理。其次。由于多租户软件主要由有经验的云供应商运营,所以能依赖那些非常经验的管理人员来提升效率。
多租户的缺点:
- 更复杂:由于一个软件需要做出极大地修改,才能支持多租户架构,而且这种修改,往往会增加整个软件在架构方面的复杂性。
- 不够安全:因为众多组织的应用和数据共享同一套软件和基础设施,如果出现机器宕机,软件出现问题或者大规模的数据被暴露等情况,将会造成更严重的后果,因为影响面更大。
几种模型
在现有的实现中,主要有三种常见的模型,而且区别主要在于采用不同的数据库模式(Database Schema):
- 私有表(图1-a):它是最简单的扩展模式,就是为每个租户的自定义数据创建一个新表。优点是简单。缺点是涉及到高成本的DDL操作,并且它的整合度不高。
- 扩展表(图1-b):总体而言,比较类似于私有表,但是一个扩展表会被多个租户共享,所以无论是共享表还是基本表都会有租户栏位。好处是比私有表更高的整合度和更少的DDL操作,但是在架构上比私有表更复杂。
- 通用表(图1-c): 主要通过一个通用表来存放所有自定义信息,里面有租户栏位和许许多多统一的数据栏位(比如500个)。像这种统一的数据栏位会使用非常灵活的格式让转储各种类型的数据,比如VARCHAR。由于在每一行中的数据栏位都会以一个Key一个Value形式存放所有自定义数据,导致通用表的行都会很宽,而且会出现很多空值,所以通用表这种方式也被称为"Sparse Column"。好处是极高的整合度并避免了DDL操作,但是在处理数据方面难度加大。
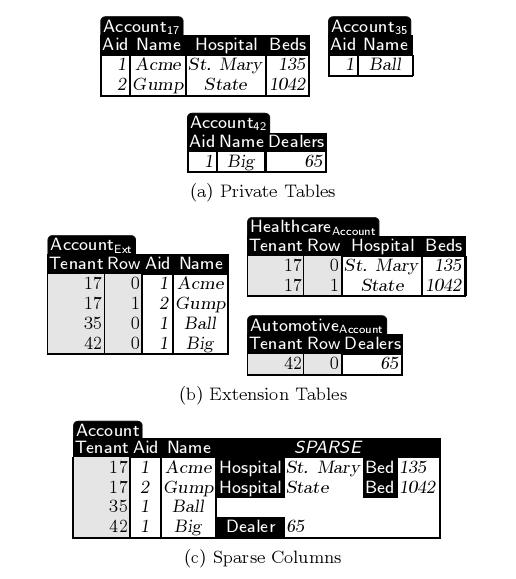
图1. 多种模式(图源自参[7])
差异与取舍
| 模型 | 机制 | 优点 | 缺点 |
| 私有表 | 为每个租户的自定义数据创建一个新表 | 简单 | 需要DDL操作,低整合度 |
| 扩展表 | 一个扩展表会被多个租户共享 | 高整合度,少DDL操作 | 有点复杂 |
| 通用表 | 通过一个通用表来存放所有自定义信息 | 极高整合度,无DDL操作 | 实现难度高 |
在实战中,具体选择那个模型,主要还是看那个模型更适合。
关于多租户的介绍已经基本结束了,下一篇将详细介绍Force.com的多租户架构。
--EOF--
本系列文章列表