对于国内存储市场来说,3PAR 是不折不扣的后来者。也是个相对陌生的存储产品,以至于其竞争对手的人员甚至都不知道这家公司已经杀入中国市场。
3PAR 在 1999 年成立,几个创始人主要出自 Sun ,前身叫作 3PARdata , 2008 年上市。要知道在存储技术领域竞争还是比较激烈的,EMC / HDS 等控制着高端存储的主要市场,3PAR 能突破技术壁垒并最后成功上市,没两把刷子那是绝对做不到的。
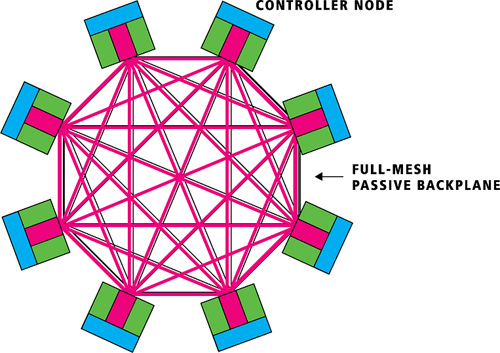
InSpire 硬件结构
3PAR 背板采用全网状的连接结构,每个控制器节点之间高速直连。因为是全网状的,所以基本上一个链路坏掉只影响直连的两个节点的通信,对其它节点无影响。每个控制器节点内置一块硬盘,用于操作系统安装。控制器节点最多可以扩展到 8 个,是 3PAR 存储最核心的组件。
相比之下,HDS 架构采用全光线交换方式(Universal Star Network),而 EMC 是采用直连矩阵方式(新一代产品采用虚拟矩阵架构--Virtual Matrix ,其实已经放弃了直连矩阵架构了)。这些连接方式的孰优孰劣历来是厂商攻击竞争对手的着眼点,能否最大限度发挥性能是用户最需要关心的。
3PAR 针对 I/O 指令和数据移动使用不同的计算芯片。I/O 指令(元数据/控制Cache)用 Intel 的芯片,而 数据移动/Cache 则使用专门设计的 ASIC 芯片来完成。
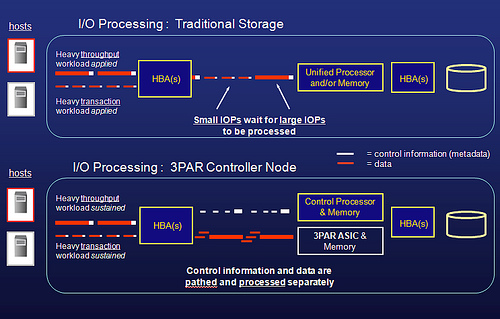
因为有专门的硬件 ASIC 芯片用于 RAID 5 XOR 校验,3PAR 号称有了其第三代 ASIC 芯片,实现的 RAID 5 是业界最快的,甚至 SATA 盘也能有不错的性能表现。(从 Oracle 公司测试的数据来看,和 RAID 10 速度的确相差无几。)
InForm 操作系统软件与虚拟化
3PAR 的操作系统叫 InForm,最初就是面向层次化的设计。与其他存储不同的是,3PAR 所有磁盘被分成 256MB 统一大小的小盘(Chunklet),可以根据需要用多个 Chunklet 组成 RAIDlet(逻辑磁盘)。因为这个独特的设计方式,3PAR 是可以很容易做到不同容量的磁盘混用,同一个 RAID 组里都可以有不同大小、不同转速的磁盘混用,这是其他存储做不到的。而且,所有的磁盘都可以利用,因为Hotspare Chunklet 以更小的单位分散在不同的磁盘上,也不再需要单独留热备盘。空间利用率可以更充分一些。
多说一句,有这个冗余机制,3PAR 更换磁盘也是与众不同:直接抽磁盘盒子(一个盒子可是四块磁盘啊),我当初看到 3PAR 技术人员这么操作真是着实吓了一跳。
因为固定大小的 Chunklet 的存在,可以将 I/O 更为均匀的分散到多个磁盘上。

对于熟悉Oracle 的朋友来说,会发现这和 ASM 的思想非常接近。因而也可以和 Oracle 数据库进行无缝集成:

因为软件做得非常具有易用性,日常管理与维护远远没有其他高端存储那么复杂,新增磁盘这种事情,都是一行命令之后底层自动处理。其实在 Thin Provisioning 方面 3PAR 也是很值得一说的,比一些厂商的伪 Thin Provisioning 具体多了。限于篇幅,不赘述。
3PAR 在美国有很多金融证券行业的客户,也有 Web 2.0 行业的客户--MySpace 。在保证 I/O 响应在 10ms 以内的前提下,3PAR 的 IOPS 能力非常优异(这才是卖点,不难理解其客户多集中在证券、金融领域)。虽然有些厂商号称能得到更高的 IOPS ,但那是在 I/O 响应时间很差的情况下的数据。要说明的是,现在随着一些存储厂商在高端服务器上也支持 SSD ,未来几年如何还要再看。
前两年 3PAR 推行所谓 Utility Storage(功用存储) 理念,现在貌似改成敏捷存储了。说实话,我觉得敏捷存储真的挺适合的,3PAR 命令行批量创建 LUN 真的很让人感觉舒服。当然,也在宣传云存储和绿色存储的理念,那是题外话了。
3PAR 原来只做中高端市场,只有 T 这一个系列,现在也开始关注中低端市场了,推出了 F 系列的产品。软硬件体系基本没变,倒是没仔细看过。
(Note: 相关图片主要来自 3PAR 公开资料.)
--EOF--