这是前一段时间《程序员》杂志采访支付宝架构师团队的的稿件。篇幅较长,此为第一部分。。
本周支付宝架构师团队一部分成员将参加 CSDN 上海英雄会,欢迎做些技术或者业务方面的交流,
尤其是支付宝的一些合作伙伴公司和潜在合作伙伴公司。
Note:提问者:《程序员》杂志郑柯。回答者:支付宝架构师团队。
能否介绍下支付宝架构团队的构成以及各位的知识结构?
支付宝架构团队里的架构师角色可以划分为首席架构师、技术架构师、业务架构师、产品架构师等、数据库架构师等。
- 首席架构师:制定公司的长期技术路线图。是公司技术方向和技术组合的重要决策者。
- 技术架构师:关注整体网站系统架构。通过技术架构对业务架构提供支撑;(系统分析员不是技术架构师,但技术架构师能够胜任系统分析员的职责)
- 业务架构师:关注业务架构。对公司战略、客户需求、内部需求进行抽象、组织、规划。关注业务的敏捷性,能够随着战略的变化而变化。
- 数据架构师:负责数据库相关的架构,数据相关的技术研究、规划、评估等。
此外,我们支付宝架构团队里面还有搜索引擎专家专门负责搜索相关的技术,有业务流程专家制定业务流程制定,流程架构开发指引等,可谓藏龙卧虎。
支付宝的架构师中,一部分是从支付宝与淘宝网的内部一线研发人员中成长起来的,在多年的实战中积累了丰富的大规模分布式互联网系统的设计与开发经验,有扎实的 Java 开发功底,熟悉各种开源系统、框架与工具,熟悉主流的企业中间件。支付宝架构团队也有一部分是来自著名 IT 企业的架构师,他们分别在数据库、高性能计算、企业服务总线、工作流、开发工具等专业领域有多年的积累。
支付宝架构师对电子支付行业知识有相当深入的了解,尤其我们的业务架构师,他同时也是会计与支付行业应用的专家。另外,值得强调的是,每个架构师也都会定期带一到两名徒弟,把经验直接传递下去,满师之后徒弟也会承担比较关键的角色,这也让开发团队的同事有更好的上升空间。
支付宝架构团队对自己的具体定位是什么?
支付宝架构团队的日常工作定位在支付宝系统高层架构的设计与优化,其职责是保障系统与公司的愿景与业务体系一致,达到关键的业务敏捷、可伸缩、高可用、性能与安全指标,具备内在的统一性、协调性与可持续发展性,支持支付宝技术团队高效率地研发高质量的产品。
为了达成这一目标,我们会创建并持续优化支付宝的业务架构与系统架构蓝图与发展路线图、参与各类外部与内部标准与规范的制定、评估与指导重大项目与重大的系统变更、主持设计并实现支付宝系统开发框架与工具、以及辅导与培训支付宝技术团队成员等。
支付宝架构团队同时是支付宝未来发展所需的关键技术的孵化器。我们会根据公司的业务方向与趋势,结合行业与技术的发展状况,产出并维护支付宝的技术愿景、技术研究整体规划与发展路线图,并主持开展前瞻性技术的研究。
支付宝架构团队也是公司决策层的智囊团之一。我们会参与公司的发展决策,站在整体业务与技术架构、技术可行性与最佳技术途径的角度,对公司重要项目的决策提供专业性的参考意见。
补充一下,支付宝架构团队一直在招贤纳士,欢迎更多技术牛人加入(Fenng 补充:另外近期在上海会有招聘会)。
架构团队与开发团队之间的沟通多么?主要集中在哪些方面?
沟通是比较多的,一方面是在项目期间会有比较频繁的沟通,主要集中在产品的系统设计是否合理、技术难点支持等方面,有的时候,架构师也会临时"下放"到项目组,与开发工程师并肩战斗;另一方面在非项目时间经常会针对开发模式、新技术走向、如何做好设计和编码等技术角度做分享与交流。
架构团队内部的小范围沟通也不少,大家经常会就一些难点进行思维碰撞、分享、交流。
我们架构组后面的白板好像很少有干净的时候 - 经常是在讨论中拓扑图画满了整个白板。
支付宝架构团队是否经常与阿里巴巴旗下其他公司的架构团队进行沟通和交流?从其他团队哪里学到的最有价值的东西是什么?
为了促进阿里巴巴旗下的各个子公司之间的技术交流,我们成立了一个集团架构委员会。集团架构委员会每个月会有一次线上交流,每个季度会有一次线下的会议交流,而且每个月末各个子公司都会在邮件列表中报告各个子公司技术研究方向和成果。
如果大家都在研究同一种技术,会成立专门的研究小组,进行针对具体技术场景的研究。通过集团架构委员会,我们可以了解各个子公司的技术方向和研究成果,做到互相促进,互相学习,技术共享。
你们认为支付宝架构最令你们自豪的是什么?为什么?
在过去的三、四年里,随着支付宝业务领域的拓展与业务规模的增长,支付宝系统也一直处于快速的增长与变化中,从最初的单一应用迅速发展成由数十个自主系统构成的高度分布又充分协同的大系统。与此同时,支付宝研发团队的规模也从最初的数人发展到现在超过百人的研发团队。在快速奔跑中保持稳定与平衡,对架构提出了很高的挑战。
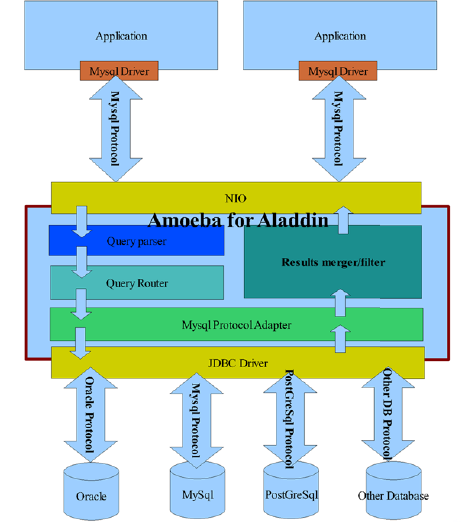
因此,我们很早就将支付宝系统建立在了面向服务架构(SOA)之上,确立了面向服务的整体业务架构,围绕着公司的基础业务建设了几大核心服务系统,并且搭建了以 ESB 为骨干、以服务框架为基础的面向服务基础设施。这些核心服务以及基础设施是支付宝系统健壮的后腰,它们的高可靠与高可用性是支付宝系统的整体稳定性的基础,它们的灵活性与可重用性支持前端业务有条不紊地创新、整合与优化,它们的可伸缩性保证了系统能够支撑持续的快速业务增长。
面向服务架构不仅是支付宝的运行系统的基础,而且已经渗透到了支付宝的研发与治理体系中,当前,这个领域仍然是支付宝架构团队的一个研究与应用的重点。
能够介绍一下支付宝的架构中用到了哪些 SOA 的思想?
支付宝从05年开始规划、研究SOA;在06年开始实施第一个SOA项目,同年引入ESB产品,对SOA相关的思想、技术进行验证和探索;经过几个项目的实施,我们完成了第一阶段的规划和目标,实现了几大核心业务的SOA化,构建了一套支撑SOA的技术平台。
从理论到实践上,都积累了丰富的经验,下一阶段,我们将会在深入业务SOA的同时,不断完善和发展我们的SOA技术平台。
在采用SOA思想的过程中,我们从下面2个方面入手:
首先,从业务层面入手,用SOA思想梳理业务架构。化解业务敏捷的要求,同时支撑支付宝的开放战略。在此之前,我们在进行业务架构分析的时候,更多的是关注业务的合理性,可行性等,在业务发展的初期,这种做法能够满足我们快速开发系统,及时占领市场的需要。在05年中,我们预见到现有的业务架构,将不能支撑我们公司快速发展的需要,例如:我们的注册会员飞速奔向1亿。此时,我们就开始探讨和规划SOA思想。因此在06年,我们果断的引入SOA思想,用SOA的思想不断重构我们的业务架构。在这个过程中,随着数次公司战略的调整,业务架构都能够灵活应对,达到了业务敏捷化的目的 -- 这也是SOA思想的核心。
业务架构的SOA化,是我们开展技术SOA的一个充要条件,没有这一步,我们将会非常艰难,甚至无从下手。
接着,技术层面的SOA,构建一个适合支付宝的SOA技术平台,来支撑业务SOA化的需要。针对支付宝的业务特点和要求,我们优先考虑实现如下SOA要素:
A:以服务为基本单元。技术平台提供与之对应的组件编程模型,业务层面的每一个服务,都能够方便的封装位技术层面额一个组件,例如:客户系统中的注册、登录等,都对应一个组件,每个组件都是独立的,在部署的时候,我们可以灵活选择和组合,可以依据SLA的要求,做出多种部署策略。
B:基于统一标准。在此,我们选择了ESB产品提供支撑,对外提供SOAP、REST、Hessian等标准的支持;对内统一采用定制的标准。
C:分布的能力。所有的服务都能够透明的分布,为外部消费者使用。
D:鼓励扩展。技术平台提供扩展的能力,例如:客户注册后的业务扩展点,业务部门要求依据客户注册来源、客户所在省、客户年龄等,进行不同的业务处理,而且这些业务点有些要求在事务中,有些要求在事务之外。如果每次新的需求出现,都在原有系统直接进行修改,那么不但可能破坏原有的业务,而且可能导致系统可维护性变差。提供扩展点功能,将把扩展逻辑和主体业务逻辑进行有效的隔离,能够彻底解决上面的问题。
E:支撑业务敏捷。支付宝的交易流具有流程类型多,流程过程繁杂的特点,业务流程每个月都会提出多种新的交易业务,同时我们的业务从单一交易业务流向整合型业务流发展。因此,我们引入了BPM相关的技术和工具,帮助我们方便,灵活的组合服务,定制流程。
--待续--