在 Web 类别下的文章
最近北京奇遇花园咖啡馆举办了一场 "Beta 技术沙龙", 关于"有道阅读器产品设计"的话题。
在杭州也没办法过去参加,倒是第一时间看到了 PPT。又问了以下,PPT 可以进行传播。所以截取了两张图(版权属于有道)学习一下。先是交互易用性问题。有道的数据库缓存策略是把当天的数据缓存起来,用 Memcached ,不知道改造过过还是默认方式使用。有道的 Ajax 交互的响应速度相对比较快。也是 用 JQuery -- 几乎快成了居家旅行必备 JavaScript 库了。

用 YSlow 分析了一下有道前端的一些策略,发现大部分都做得不错,挺专业。Web 服务器是 Apache (不是 Nginx ),不过大部分图片设置为一周过期有些问题,太保守了,其实图片不过期也没啥问题,RSS 阅读器中的静态文件其实几乎不变化--除了用户的头像。应该说,判断一个网站是否合格,看看前端优化做得如何就可以了,如果做的不好,要么是太有钱,不担心带宽和计算资源的浪费,要么是根本不考虑用户的使用感受。

对于抓取的数据全部保存的问题,我不知道有道对 Feed 抓取过的内容更新问题如何处理。谁让咱没去现场呢,等下次有机会再了解一下吧。最后一点期望:有道什么时候能把订阅数让 FeedBurner 正确识别? 相信对大一点的网站 Google 多少能重视一点吧 ?
--EOF--
今年以来,一些小型但有针对性的技术沙龙逐渐活跃起来了,嗯,杭州,在 5 月份之后也将开搞,敬请期待。
肯定有人问哪里有 PPT ? 访问 Club.blogbeta.com
另参见:霍钜的 《关于有道阅读的beta技术沙龙》
收到邮件说 Spawn-fcgi 成为独立项目,并且预发布了 1.6 版本。
原来很多人都用 Lighttpd 的 Spawn-fcgi 进行 FastCGI 模式下的管理工作,不过有不少缺点。而 PHP-fpm 的出现多少缓解了一些问题,但 PHP-fpm 有个缺点就是要重新编译,这对于一些已经运行的环境可能有不小的风险(refer)。
原来 spawn-fcgi 版本也比较乱的,期待独立后的项目能更稳定一些。这会给很多 Web 站点带来便利。
--EOF--
在 Web Analytics 的几种方法中,分析 Web 服务器日志(Logfile Analysis) 与页面标记方法(Page Tagging/JavaScript Tagging, 也有称之为"打点")相对更常见一些。今天发现一个关于二者的对比表格,感觉还是挺有帮助的,粗翻了一下,留作参考。
{kind=link}
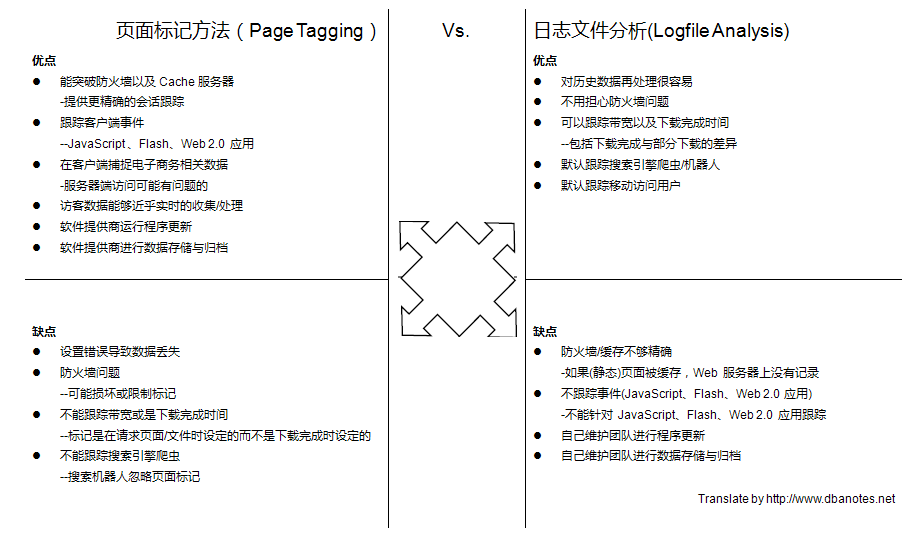
(点击可看大图)
Page Tagging 的方式对业务控制(比如特定业务预警)更为灵活一些。其他的方法比如 Web Beacons(Web Bug) 的方法在 Web 1.0 的时候还是挺普遍的,对付当前的各种新型 Web 应用已经无能为力。
在设计 Web 应用的初期架构师就应该考虑 Web 分析的方法接口,就像在程序中预置性能调试接口那样,早点考虑,会少许多麻烦。
关于 Web Analytics,仍然存在许多误解与误用。冷暖自知吧。
--EOF--
前几天 3G 牌照下来,一时间 Buzz 信息很多,不过关于 3G 对 Web 技术影响的分析倒是并不多见。今天再次读了一遍这篇 2009 移动 Web设计趋势 (Mobile Web Design Trends For 2009),加上这几天在分析使用 iPhone 上的某些 App 设计,还是记录一点笔记吧。
这篇文章提到了如下五点:
- 简单的可选项(Simple options) 如无必要,勿增实体。基本的、核心功能就行了。
- 留白(White space) 我觉得 UCWeb 针对 iPhone 的设计就很一般,完全是把 iPhone 当成小屏幕显示器设计的。堆砌的网址站看起来不方便,点击起来并不方便,倒是应该弄个 LOGO 或许更好。
- 少用图片(Lack of images) 这倒是和上一条矛盾。能少用就少用,而不是不用。而用了图片,如果方式不合适,还不如不用。
- 用子域名而不是用 .mobi 域名(Sub-domains instead of .mobi or separate domains) 精简域名长度,精简!用 "i." 就很好,别用 "mobile. "。
- 内容优先(Prioritized content) 只有设计是没有用的。
我的额外建议:
- 可点击的目标锚点一定要大。因为你的手指肚更大 :) 如果一个手指尖范围内还有其它可点击目标,很容易误点。最简单的方式就是看看 iPhone 自己桌面菜单设计。而我之所以说 Taobao 商城 iPhone 版设计的不错,也是因为这一点考虑得很地道。Gmail for iPhone 的设计上,用户浏览邮件内容的时候,那个 "Inbox" 的按钮就设计的非常不好。很容易误点击到 "Archive" 按钮上。
- 分页设计 对于分页的链接,一定要隔开一些,如果"上一页"、"下一页"挨在一起,用户会很困扰。毕竟,手持设备没有鼠标,用户不可能具备"精确点击"的能力。
- 登录框设计 在 iPhone 上登录某些站点是非常痛苦的一件事情。可考虑的事情:如果用户 ID 是邮件地址的话,是否考虑无需用户输入"@" 字符? [iPhone 2.2 固件已经改进了许多]
另外,2009 移动 Web设计趋势 (Mobile Web Design Trends For 2009) 还提到了设计中的常见挑战以及需要慎重考虑的地方,这篇文章信息量还是挺大的。
--EOF--
唠叨完了,发现基本上是针对 iPhone 说事儿的,我还不是标准的移动互联网用户。
且说我使用有些网络服务的时候常常能遇到比较怪异的问题。昨天在某个页面遇到个 Redirect Loop 错误提示:
Firefox has detected that the server is redirecting the request for this address in a way that will never complete.
同样的问题,同样的页面,同样是 Firefox 浏览器,以前就遇到过,提交给相关负责人之后没了响应,后来也忘掉了。同事说是我浏览器版本的问题,后来发现这和"是否接受第三方 Cookie" 的设置有关:
[x] Accept cookies from sites
[ ] Accept third-party cookies
我的浏览器不接受第三方 Cookie。设置接收后该页面显示正常。
搜索了一下,发现之所以该页面是这样,还是因为页面用了 iframe 而导致的问题,比较通用的办法是设置 p3p http header 。
这个 P3P(Platform for Privacy Preferences Project),要搞明白,可真是有点小孩没娘,说来话长。简单的说,就是个协议,通过其声明它是好人,允许我收集浏览器用户行为吧... 可现实中,大家都可以说自己是好人,背地里没准儿干啥坏事呢。这就是其分歧所在。[参考] 国内多数网站,都不关注这个 P3P。隐私问题可能没国外(微软的隐私声明)重视吧。
再说 Firefox ,过去的几个大版本中,对 Cookie 的处理方式还是有很大变化的。
这个问题影响最大的还是 Facebook 等开放平台的应用,使用了 iframe 就会遇到(eg: FriendFeed 遇到过,估计还比较头疼)。
对于浏览器来说,第三方 Cookie ,默认情况下,浏览器接受与否,是个大问题。如果不接受,会给很多用户带来混淆,如果接受,则在隐私问题上,有很大的挑战。
实际上,Firefox 的开发者在这个地方的处理方式也在摇摆当中(参见), 不过能确定的是 "the ability to make decisions based on p3p policies was removed for firefox 3"。
各家浏览器在这个地方都可能有 Bug。比如 IE7 曾经有的 Cookie 问题,IE8 Beta 也有类似问题。
或许,最好的办法就是别去种这个 Cookie 了... 网站开发者,你们愿意么?
--EOF--
更多阅读:Windows Internet Explorer (Pre-Release Version 8) Privacy Statement
微软 Cookie 说明
另请参见文本后面 axis 同学的留言。
 没看这本书之前我以为我懂 Web 分析,看了之后才发现之前其实并不明白。
没看这本书之前我以为我懂 Web 分析,看了之后才发现之前其实并不明白。
算起来,用 AWstats 做了几年的小实验,尽管一些基本的东西是有所了解,但如果要详细说明背后的含义,还是并不清晰。这可能不是我一个人的感受吧? 我遇到过一些做 Web 分析的同仁,整天看网站数据报表,也看不出什么东西来。尽管我们常看到 Web 分析工具的更新,但国内互联网的 Web 分析思路似乎并没有"与时俱进"。 不管承认与否,毕竟是现实一种。
普及这本书,我想能有效避免 Web 分析中的一些误区,以 PageView 为核心的 Web 分析时代应该已经过去。结合自己的实际业务,通过数据去了解客户,真正做点能起到"正反馈"的事儿,而不是到了节假日弄一些无聊活动疯狂弹出一些用户烦透的垃圾页面。这对你们公司也是莫大的损失。
负责网站数据分析的主管啊经理啊总监啊都把这本书偷着买回去仔细读两遍,然后整点靠谱的针对 Web 的 KPI 出来,也让下面的员工心里服气你还算个合格的管理者。把这本书当作了解 Web 的另一面镜子(如果是从传统行业过来的话),通过另一个角度(数据)观察 Web。
此书翻译质量一般...但我想不影响阅读。
Web Analytics,An Hour a Day ,不需那么多,只要一点点。
--EOF--
作者 Avinash Kaushik ,感兴趣的话还可以观看他的相关采访视频。更多信息访问豆瓣上的 精通Web Analytics页面,如果买书直接点击豆瓣上的链接去买吧,也算支持豆瓣了 :)
又及:这本书也被我列入豆列 Web 2.0 网站架构不可或缺的图书。
还是继续这个网站运维的话题吧。前面谈了知识管理与积累,这次谈一下运维过程中的自动化管理。
在进行这篇的扯淡之前,让我想起了《太平广记》里的一个《 板桥三娘子》的故事,姓赵的客商窥探到客栈老板娘三娘子在小箱子中取出小孩玩具大小的木头牛,木头人,喷口水,木头人、牛开始犁地耕作,撒一粒荞麦种子,木头小人种下,不一会儿,荞麦长成开花结实,木头人收割,乃至磨成面粉。然后三娘子把木头牛、人收入箱中,用得来的面粉做了数张面饼。多么好的一个自动化场景呀。
自动化的目的
自动化管理是网站规模化之后必须要面对的问题。为什么要自动化?肯定不是为了炫技,针对一个发展中的网站来说,自动化的主要目的还是为了节省维护成本,提升运维成熟度能力。另外一个经常被忽略的收益是能让运维工作更有趣味性一些,不那么无聊,不无聊的有益副作用是减少人为出错的可能。
自动化针对的范围大致可以分为安装自动化、部署自动化、软件发布自动化、升级自动化、监控自动化等几个方面。优化自动化? 别,这个稍微"高级"并且不靠谱了一点。
自动化要解决的问题是 N 次循环的过程,如果 N 不具备延续性,那么自动化未必有必要。比如某个过程可能只是短时间内需要临时进行几次,是否有必要将其自动化就有待于商榷。如果计划和开发自动化过程的成本高于非自动化成本就没必要了。
开发自动化过程
如果看过古龙的小说,他曾经描述过几个有趣的懒人,懒人造了一些木头人和机关来帮自己干一些不愿意做的事情。自动化多少就是"懒人"要做的事情,因为懒嘛,所以才会想办法节省时间和其他成本。一般来说,这个过程的开发者也是使用者,所以没必要一定要按照所谓的项目过程去走,但是开发者必须能够产出一份文档给同团队的伙伴(如果有的话)。
考虑到多数的网站运维可能都是在 Unix like 环境中的,而 Unix 的哲学思想之一就是"Write programs that do one thing and do it well",每个过程只做一件事情就很关键,"功能单一的自动化模块"是有必要的,把不同的模块拼装起来再去完成更复杂的需求。
Unix 相比 Windows 来说,天生具备可自动化能力。如 Shell/BASH(自动化日常操作)、CronTab(自动化任务调度) 、Expect (自动化交互场景) 、rsync(数据远程同步)等 啊都是一些需要注意的技术内容。
优化自动化过程
自动化过程一般要有个生命周期,定期升级、优化也是有必要的。面对不同的应用场景应该逐渐改进自动化的可用性。
示例:自动部署 Linux
对于批量的 Linux 安装,RedHat 提供有 Kickstart Installations 自动安装解决方案,不过该方案相对比较繁琐,前不久推出的 Cobbler 是让人眼前一亮的好工具(参见 hutuworm 的介绍文章)。我一直怀疑 Cobbler 是中国人命名的项目,因为 PXE 发音为"pixie"(皮鞋),而 Cobbler 的中文意思是"补鞋匠"。
OS 安装完毕之后的软件安装、更新是个麻烦事。在一个 Linux 的环境中,SA 一定不要为软件相互依赖性浪费太多的时间。什么 YUM、APT、YAST 啊,能用就用上。别太迷信自己编译软件所能带来的优化收益,实际上犯错的几率更大。达到某个规模后,本地建立、维护一个软件资料库(repositories)也是有必要的。
Linux 软件安装进化之路:
手工预编译-->RPM-->APT 等工具
已经进化到更好的阶段了,没必要还走着老路在原地折腾。
其他参考:Flickr 运维曾经采用 System Image 来自动化 Linux 相关的的运维工作。或许也可以尝试一下。
在系统配置管理(别混淆到另一个配置管理上去)方面,其实 cfengine 就挺好用的。更多类似工具参考这个比较列表。
标准化,减少后续维护成本是节省人力资源的一大法门。
自动化的一些风险
必须要承认的是,自动化有的时候是容易带来一些风险的,比如"冲掉"原有配置文件信息,不恰当的自动化脚本给系统带来额外负载等,在运维过程中需要不断总结经验。(又落入俗套)
这方面值得推荐的一本书是《UNIX和Linux自动化管理》,借鉴一下其中的思路和方法。
对了,补充一下前面的《板桥三娘子》的故事发展,三娘子的面饼如果被客人吃下,则会变成驴...... 同样,自动化有的时候会把人陷进去的,运维人不要变成自动化的奴隶。
这个话题还需要继续下去么? 我再想想 ...
