在这里给各位朋友以及各位读者顺路拜年啦!
新年快乐,身体健康,诸事和谐,万事如意!
收到了不少朋友的短信,短信内容不乏精彩之作,有豪放的,有婉约的,有古典的,有现代的,我这个人比较懒,就不一一回复了,心里有大家。提醒各位发短信别忘参考一下拜年短信指南。

2009 年的风景与道路...
--EOF--
在这里给各位朋友以及各位读者顺路拜年啦!
新年快乐,身体健康,诸事和谐,万事如意!
收到了不少朋友的短信,短信内容不乏精彩之作,有豪放的,有婉约的,有古典的,有现代的,我这个人比较懒,就不一一回复了,心里有大家。提醒各位发短信别忘参考一下拜年短信指南。
2009 年的风景与道路...
--EOF--
传闻 Google 从 Intel 订购芯片,要求更具耐热性,要求 CPU 能在超出标准工作温度 5 摄氏度情况下运行。这样可以大量节省空调制冷带来的电力费用。
最近的另一个消息是 Google 在号召厂商采用 12V 电源的主板。节省功耗。
空间和电力是 IDC 头疼的两个地方,对于节省空间,Google 的服务器设计趋势是在一块主板上设两个服务器 ,有些类似硬件上的虚拟化。
Google 的这些举措其实也是其他上了规模的公司要走的路,肯定也会对 IDC 产生及其深远的影响。昨天和朋友在聊省电的事情,我当时能想到的也就是低功耗硬件, 比如低功耗 CPU、采用SSD、硬盘自动降速等几个有限的方式,倒是没想到更耐热的 CPU 这一点,而面向 IDC 的硬件集成这也是个很好的参考。
参考资料:
--EOF--
接上一篇。这其实是一篇综述文章 :)
可能有些企业已经在战略中加上了云计算这个关键字,问题是,真的需要那么多云计算么? 如果在技术上、规模化不能有效的节约成本,那么跟风建设云存储服务是缘木求鱼。更多的企业是自身的存储建设都远远不到位,大谈云存储无疑是痴人说梦。至少在国内,我们的基础建设还和国外有一段距离,而内容审查与一些政策上的限制又会增加建设、运营成本。
回答这个问题之前,我建议先看看服务提供方是否真的是云存储服务,如果只是炒炒概念,用老的架构支撑,换汤不换药,那还是谨慎为妙。企业如果不能从技术上做些本质突破而节约成本,那么成本肯定要转嫁到消费者身上,如果消费者不买单,那该服务如何能长久? 和我们现实生活中很多山寨 IDC 类比一下就知道了,动辄听到某主机托管商一夜之间蒸发,用户欲哭无泪的事情。
如果使用云存储服务,不妨和竞争对手使用同一家服务商。出问题的时候大家都出问题,保证始终处于同一起跑线。
在国内,短期内还看不到有规模的云存储服务商。由于网络的问题,企业用户也不太可能去使用国外的服务(不排除将来 Amazon S3 这样的服务能在国内提供服务)。期待在未来的一段时间能看到一些变化,但这恐怕只是乐观的想法。
时值全球经济的寒冬,能够为用户省钱的服务相信也应该能够赚到钱。从用户的角度上看,云存储解放了自身的生产力,能够允许中小创业团队集中精力做发展业务,只要不形成恶性竞争,应该不用担心盈利的问题。
就以 Amazon的 S3 来说,基本上也很好的展示并实践了 Web 2.0 长尾理论:利用企业建设剩余的存储以及网络带宽能力而为广大中小网站提供服务,前途大好。相信 Google 推出类似服务也是指日可待的事情。但这个市场内应该不会出现过多的有力竞争者,有些存储厂商(比如 EMC) 也在进入这个领域,数据存储不是问题,但网络能力可不是那么好解决的事情。
从我们前面提到的云计算中的存储特点来看,SAN(存储区域网络)产品就暴露出一些不适合的应用场景,毕竟 SAN 是面向集中式计算的架构。另外,大家也都知道 SAN 产品一般不便宜(现在也有厂商在力推低端海量存储产品,后面会介绍),而且,主机端如果用 HBA 卡,也会进一步提高成本;SAN 面向传统企业应用而设计的扩展能力难以满足云计算的需求。
目前尽管已经有一些企业在做集群存储然后打包出售,但相对还是在起步阶段。至少现在还看不到真正集群 SAN 产品的出现。当然,如果对云计算的存储部分不计成本的话,SAN 仍然可以在云计算中发挥一些作用,这倒是中了存储厂商的下怀。
不管怎么说,RAID 这个 SAN 中的概念在云存储中已经绝对不适合了。
有业界评论说集群 NAS 可能会演变成云存储的通用架构,我怀疑这是不是 Sun 公司的宣传手段,因为这事实上宣布了 ZFS 将是云存储中的一个关键点。
从现有的情形看,或许会有越来越多的在线存储服务拥抱集群 NAS 。但这不代表集群 NAS 前途光明能够在云存储大展拳脚。集群 NAS 最大的问题是海量数据的寻址是个麻烦事儿,然后是扩展性与容错性的问题,底层的容错性如果通过硬件来做,那么成本无疑会上升,这恐怕是企业不愿意接受的。
在开源领域,以 MogileFS 为代表的分布式文件系统能够用于一些相对规模较小的分布式存储场景,很多 Web 2.0 自己的分布式存储就是借鉴 MogileFS 搭建的,不过毕竟 MofileFS 的Meta 信息仍是集中存储、管理的,在更大规模恐怕有些吃力。
此外,Kosmosfs(http://kosmosfs.sourceforge.net/)、Lustre(http://www.lustre.org) 等也都在不断发展中,相信能够给有兴趣研究云存储的技术人员一些借鉴。也有一些软件厂商将其专有的分布式文件系统和存储打包在一起销售,而存储厂商也有的在结合自己的存储产品做一些尝试。目前还很少有相对成熟度的东西进入用户视野。
更多分布式文件系统列表参见维基百科的文件系统列表介绍。
尽管我们接触不到 Google 大名鼎鼎的 GFS (Google File System),但我们能免费获取 Hadoop 的 HDFS (Hadoop Distributed File System)。HDFS 相对上述的 ZFS 来说,属于专门针对廉价硬件设计的分布式文件系统,在软件层内置数据容错能力。Hadoop 目前的案例多数用在数据分析与并行计算上,倒是很少看到有支撑给互联网应用的数据服务,但相信随着其在开放环境中的快速成长, Hadoop 将不断壮大。
(HDFS 架构示意图. from: http://hadoop.apache.org/core/docs/current/hdfs_design.html 关于 Hadoop 也请参阅《程序员》杂志 2008年10月刊的文章。)
云计算中存储的起步容量,我们不妨按照 1PB 可用空间来准备。近年来,随着磁介质存储能力的提升,企业存储的价格也是一降再降,$2.00/GB 的底线早已突破,现在Sun 的Thumper 声称可以达到 $1.20/GB 的成本。(注:企业存储[不是个人消费品]的磁盘价格一降再降,而且有很重要的商业因素,具体的成本应该还要更低一些,只是不知道哪位朋友有更为准确的数字)
粗略估算一下,2PB 的原始容量成本大约是 250 万美元左右(List Price)。单位机柜空间密度最高的已经能够做到4U的机存储48TB的原始容量(目前能看到密度最高的了),这样最小只需要大约 45 个 4U 的机柜空间。其他方面,加上本地的工业电力价格,大致的硬件总体开销还是可估量的。软件方面,这个存储本身是基于 Sun 的 ZFS,内置的操作系统,成本也是可以控制的。
在山寨精神盛行的今天,没准儿已经有人在搭建一套山寨版的云存储方案呢。比如目标定在 1PB 可用容量,预计至少需要如下的东西:
选择廉价的刀片服务器(自己"生产"就不必了),内置足够多的大硬盘,硬盘速度无所谓,预计每台机器预装4T容量(1T*4,坏了就整台机器替换),大约需要 500台服务器,总容量2PB,确保每一份数据都至少冗余在另外的物理机器上,冗余后,起码能得到1PB容量(如果备份的数据启用压缩,没准儿能提供更多空间呢)。机架物理空间怕是需要 1000 U多一些,每个标准机柜是42U,怎么也要准备 25 个机架吧,再加上网络交换机什么的... 然后是电力与空调散热问题。
再弄一套 Hadoop ,定制一下跑起来 ...当然,山寨与否,关键是拼技术团队,一味的拿来主义注定只能跟风。
其实,这篇文章也是一篇山寨文。
--EOF--
这是去年发在《程序员》杂志的一篇文章。当时写得比较急,现在看起来,有些观点有些武断。仅供参考。
引言, "The one that is without any tradeoff is to have the logical storage master up in the cloud" by Bill Gates.
2008 年的 IT 界,云计算是个热词。很多企业都在宣称自己提供云计算服务,很多人也都在讨论云计算(一些明显是凑热闹的,比如所谓的"云安全"),从业界公认的几种云计算的服务能力看,都绕不开存储这个基础支撑组件,dSaaS(data-Storage-as-a-Service) 更是把存储提到了首要的位置。而从我们目前能得到的信息来看,在存储层已经解决很好的,恐怕也只有 Google 和 Amazon 两家,至于其他公司可能都还在路上,即使是微软,尽管也有自己的 Dryad ,但是实际上,仍然处于理论阶段,产品化的路还有点距离。

上面表格中的举例仅仅是为了举例,如果某家已经 "云计算了" 的公司大名不在上面,并非该公司"云"的不够彻底,应该只是笔者眼光差的原因而已。
根据 EMC 公司赞助 IDC 进行的研究计划 "Digital Universe" 的分析报告,在整个 2007 年,我们这个世界生成、占用的数字信息及复制总量大约是 281 Exabytes (1 Exabytes=1024 Petabytes ,1 Petabytes = 1024 TB 这里换算都按照二进制的换算),这个数据平摊到地球上的所有人,大约是每个人 45 GB的数据;截至到笔者写稿的时候,2008年到现在整个世界已经生成了大约 374 EB 的数据(可以到 "Digital Universe" 页面查看最新的数据,也可以下载一个评估工具,看看自己产生的数据是大约如何);到 2011 年,每年产生的数字信息大约是 1800 EB,10倍于2006 年产生的信息量。做为对比,Google 每天处理的数据大约是 20 PB 的样子,Google 的目标是要组织所有的信息,看来并非易事。
其他可参考数据:据美国国家档案馆工作人员估计,布什政府电子档案存储量大约为1亿GB,这一数字约为前总统克林顿两届政府档案总量的50倍,是国会图书馆2000万册编目图书内容总量的5倍。
每年激增如此庞大的信息量,加上已有的历史数据信息,对整个业界的数据存储、处理带来了很大的机遇与挑战。通过该研究能看出,在可用存储之间与信息生成总量之间不是严格匹配的,一方面多媒体领域信息增长过快,一方面因为不合理的存储分配、占用情形比比皆是。例如研究表明一封大约 1M 的邮件发出后,经过不同服务器的存储、备份、归档等最后总体占用空间竟然达到惊人的 50M 之多。正如云计算的初衷是为了充分发挥计算机闲置资源,提高总体使用率以便达到经济效益,云计算中的存储方面也应该能有效提高存储利用率而进一步创造价值,盲目的复制、堆积数据是没有出路的。工业界提倡节能减排,其实 IT 界应该提倡一下节约存储了。
其实,什么是云计算都很难有一个权威的定义,笔者在这里更愿意把"云计算中涉及的存储"简称为云存储(Cloud Storage)。云存储本身离不开云计算,更多的时候云存储是做为云计算的一个支撑组件。
云存储不是简单的在线存储或是网络硬盘,在线存储服务只是云存储能够提供的众多服务中的一种而已。
云存储至少应该能够具备如下特点:
要建设成功的云存储系统,高扩展性、高可靠性的分布式文件系统是一个关键因素。而硬件问题反而是次要的。
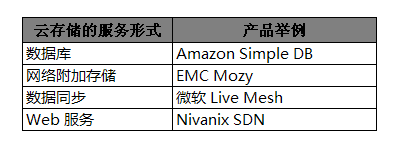
云存储的服务形式见上表。
未完待续...
前不久写给《程序员》的一篇文章里,个人预测在 2009 年,SSD (Solid-State Drive,固态盘) 在企业级市场能大展拳脚。上周参加了 EMC 的一个会议,提及了 SSD ,EMC 存储产品对 SSD 的引入也有一年了,做点 SSD 的科普知识应该是有必要的。
很多人对 SSD 的误解是:既然你可擦写次数有限制,比如 200 万次,那么不是没几天不久坏掉了,怎么说使用寿命还比物理硬盘长呢?
Wear Leveling 是有效提升 SSD 的 MTBF (Mean Time Between Failures)的一种技术手段。我们都知道木桶原理,对 SSD 硬盘也是这样,如果不停的对某个 Cell 擦写,那肯定很快就报废。 Wear Leveling 的基本思想就是利用算法保持所有的可擦写单位的次数是近似均匀的,这样就把写次数均匀的分散到各个 Cell 上。
Wear Leveling 翻译似乎还没有统一,有翻做均匀磨损、磨损分级、换位写入等。
对 Wear Leveling 粗略一点的描述大致是:假设更新某个数据块,假定8KB ,而可擦写块(erase block)是 256 KB,那么定位到当前数据位置后,将找个没写过或者写过次数更少的可擦写数据块写入,并不是对原来的位置反复更新。Wear Leveling 算法的效率直接影响 SSD 的寿命。
而 8K 到 256 KB 这个过程实际上是加大了 I/O 操作,称之为 Write Amplification (写放大)。当然 SSD 厂家另有其他技术尽量减少写的频率。
用一句话解释:擦写块(erase block)比较大。
很明显这样做的目的是减少擦写次数,提升 SSD 寿命。但也影响了数据写入速度。
这个我也不甚了了,猜测是因为 erase block 多数是 2 的幂次的缘故。物理硬盘的尺寸由来我也不甚清楚。
这个问题太容易给用户带来疑惑。个人认为要依赖应用的特点和设计。对于合适类型的数据,基本不是问题。但对于某些特定的数据类型,那可能是灾难(比如数据库的 Redo Log)。
是曙光,但不会是银弹。对于密集写入的数据库应用来说,SSD 可能不会带来更多的好处。但是对于密集读的应用,那是有可能带来数量级上的性能提升。在未来若干年内,好的数据库应用仍然严重依赖于设计人员的能力和数据库管理员的优化技巧。
此外,还要期待数据库厂商针对 SSD 进行软件级别的优化。
典型的废话答案应该是:这取决于你的具体情况。
要看性价比,EMC 最早引入的 SSD ,性能是普通硬盘的 30 倍,价格大约也是 30 倍。而现在,在企业级市场,SSD 已经降到大约 10 倍普通硬盘的价格。如果再低一些,那绝对是比较有吸引力的。
--EOF--
其中观点仅供参考。SSD 有风险,玩家谨慎操作。而这篇文章中的有些观念有实效性,细节也可能不够准确。
Note: 这里的 SSD ,是说面向企业应用而不是面向个人消费品的。
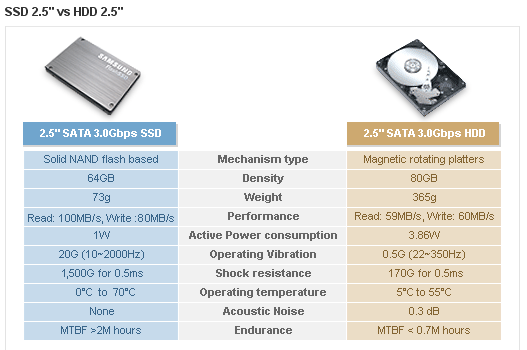
再增加一个图:
前几天 3G 牌照下来,一时间 Buzz 信息很多,不过关于 3G 对 Web 技术影响的分析倒是并不多见。今天再次读了一遍这篇 2009 移动 Web设计趋势 (Mobile Web Design Trends For 2009),加上这几天在分析使用 iPhone 上的某些 App 设计,还是记录一点笔记吧。
这篇文章提到了如下五点:
我的额外建议:
另外,2009 移动 Web设计趋势 (Mobile Web Design Trends For 2009) 还提到了设计中的常见挑战以及需要慎重考虑的地方,这篇文章信息量还是挺大的。
--EOF--
唠叨完了,发现基本上是针对 iPhone 说事儿的,我还不是标准的移动互联网用户。
且说我使用有些网络服务的时候常常能遇到比较怪异的问题。昨天在某个页面遇到个 Redirect Loop 错误提示:
Firefox has detected that the server is redirecting the request for this address in a way that will never complete.
同样的问题,同样的页面,同样是 Firefox 浏览器,以前就遇到过,提交给相关负责人之后没了响应,后来也忘掉了。同事说是我浏览器版本的问题,后来发现这和"是否接受第三方 Cookie" 的设置有关:
[x] Accept cookies from sites
[ ] Accept third-party cookies
我的浏览器不接受第三方 Cookie。设置接收后该页面显示正常。
搜索了一下,发现之所以该页面是这样,还是因为页面用了 iframe 而导致的问题,比较通用的办法是设置 p3p http header 。
这个 P3P(Platform for Privacy Preferences Project),要搞明白,可真是有点小孩没娘,说来话长。简单的说,就是个协议,通过其声明它是好人,允许我收集浏览器用户行为吧... 可现实中,大家都可以说自己是好人,背地里没准儿干啥坏事呢。这就是其分歧所在。[参考] 国内多数网站,都不关注这个 P3P。隐私问题可能没国外(微软的隐私声明)重视吧。
再说 Firefox ,过去的几个大版本中,对 Cookie 的处理方式还是有很大变化的。
这个问题影响最大的还是 Facebook 等开放平台的应用,使用了 iframe 就会遇到(eg: FriendFeed 遇到过,估计还比较头疼)。
对于浏览器来说,第三方 Cookie ,默认情况下,浏览器接受与否,是个大问题。如果不接受,会给很多用户带来混淆,如果接受,则在隐私问题上,有很大的挑战。
实际上,Firefox 的开发者在这个地方的处理方式也在摇摆当中(参见), 不过能确定的是 "the ability to make decisions based on p3p policies was removed for firefox 3"。
各家浏览器在这个地方都可能有 Bug。比如 IE7 曾经有的 Cookie 问题,IE8 Beta 也有类似问题。
或许,最好的办法就是别去种这个 Cookie 了... 网站开发者,你们愿意么?
--EOF--
更多阅读:Windows Internet Explorer (Pre-Release Version 8) Privacy Statement
微软 Cookie 说明
另请参见文本后面 axis 同学的留言。
看到了豆瓣内测中的新的九点服务。从老的九点,到广场,再到重新上阵的九点,我们多少能看出豆瓣团队在去中心化路上的挣扎。豆瓣对中心化的内容非常反感,但任何一个网站,必然要存在中心化内容,如何把这部分内容让有需求的用户有效获取才是网站设计者需要做的地方,人为的打造或者误导用户看到一些伪中心化内容则是不可取的--这也是国内其他站点所一贯采取的方式,美其名曰--网站运营。
新的九点直接划了四个频道: 文化、生活、科技、趣味,代替原来需要猜谜的四套、二套等是个不算改进的改进,对于任何功能,不应该挑战用户理解力,好的应用必须能适应 80% 的大众用户,另外的 20% 所谓高端用户其实会有自己的玩法。
新的九点,我建议应该把读者对内容的反馈(如推荐语, 评价)有效展现出来。这也是旧版九点我一直不太满意的地方。比如如果有人推荐了某篇文章,并留下了评价的话,我期待的是这个交互内容能被用户有效的获知。但旧版九点基本上只能看到推荐人数,看不到推荐语--推荐语在广播那边,这就抑制了用户的互动性质。现在的九点,看上去仍然像一份电子报纸。我期待能更好玩一点。
今天在奇遇花园咖啡馆和詹膑、郝培强聊天也提到了豆瓣新九点,说起抓虾和鲜果的类似页面,我也表达了同样观点。网易的新闻其实是个很好的借鉴模式。尽管这个聚合页面是抓取来的内容,但是应该允许用户进行方便无痛的反馈,这部分内容如果要提供给内容提供者也并不复杂,开发一个 Widget 脚本就几乎可以了。这样的做法其实也会给 Blog 作者带去一定的流量,如何判断一个聚合应用是否会受到内容提供者欢迎? 能给他们带去流量才是王道。
新九点似乎也在尝试增强阅读器的功能:
我更愿意把这个功能看作九点对用户关心内容的另一个角度展现。
豆瓣去年的每次改版都引起用户不小的反弹,这或许某种程度上说明对产品不同方向的尝试。这次新九点应该骂声会小很多。或许,现在的九点仍然还在继续进化中,但不管怎样,还是期待能有一个适合国内用户的 Digg + Techmeme 产品的出现。
--EOF--
 记得看过一个数据,中国软件企业 50人以下的公司数量达到 70% 以上,规模普遍偏小。我想这 70% 中至少有 80% 还是小作坊的研发模式,"三五个人,十来条枪",有一部分企业偏居一隅,远离信息技术发达城市,摸索着发展团队,其中甘苦谁人能知?
记得看过一个数据,中国软件企业 50人以下的公司数量达到 70% 以上,规模普遍偏小。我想这 70% 中至少有 80% 还是小作坊的研发模式,"三五个人,十来条枪",有一部分企业偏居一隅,远离信息技术发达城市,摸索着发展团队,其中甘苦谁人能知?
阿朱这本《走出软件作坊》,以切肤之痛,现身说法,是一件很有价值的事情。当然,此书未必能解决很多公司的问题(也没有任何书能做到这样),但至少能引起多数人共鸣,引发大家进一步思考与探讨,少走弯路,这正是当下缺少的。书店里管理学图书汗牛充栋,有的告诉你把信送给加西亚,有的告诉你不要有什么借口,还有的说是办法比问题多...... BULLSHIT! 凡此种种,多数是管理者写给管理者的洗脑心灵鸡汤,此类图书,多半中了成功学的流毒,读后三天如打了鸡血兴奋,三天之后打回原形。而阿朱毕竟是过过苦日子的,说白了,是做过咱技术民工的,久病成医,现身说法,疗效尤佳。
打造软件团队,或许很多人以微软、IBM 等巨擘为师,但文化隔阂在哪里摆着,差之毫厘,谬以千里;也有人从实践中来,黑猫白猫,抓到耗子才是好猫,我想阿朱属于后者。有的时候,看了阿朱说的话,挺生气,比如说技术人员与老板的关系,"老板把你提上来就是为了让你给他赚更多的钱..." ,也挺让人绝望,但这也是实话,早点认清了这一点,摆正心态,积极面对,反而更有利于把自己全身心投入,从而打造一个老板赚钱、下属满意的团队文化。否则一味抱怨,也不会解决问题,也就失去了改造团队的机会。最近,自己也多有反思这样的事情,一声叹息。
最后,从这本书里学到比较多的两个章节是关于"售前经理"和"演示方法"(记得在北京 SD 2.0 大会的时候雷军也特地提到了这个章节)。看过很多所谓大公司的售前做演示,出色的不多,糟糕的倒是看到不少。阿朱这两个章节的内容可以拿去给这些大公司做一下培训。
希望阅读这本书的朋友都能从此书受益,让自己的团队不再山寨,顺利走出软件作坊。也期待阿朱同学能通过网络和大家分享更多的心得。
--EOF--
每年给自己一点期待。去年的 Wish List 算是实现了一半。
0) Panasonic's Lumix DMC-LX3 有个轻便一点的相机,可以随时随地拍点有趣的东西。
1) Google G1 Android 想测试一下这玩意儿,琢磨一点移动互联网用户体验的东西。现在 iPhone 其实没那么好玩儿了。
2) Eee PC 1000H 估计今年用小本子的人更多了。物美价廉,伪 Geek 必备佳品啊。
3) 没有了
避免变成消费主义者。另外,经济危机了,告诫自己别奢求太多。没人知道今年会怎样。
可以通过赞助或者购买网站广告来帮助这个家伙完成心愿 :)
--EOF--
更新:2009 年 1 月 13 日,老婆给买了一个 LX3 。第一个愿望达成。
 没看这本书之前我以为我懂 Web 分析,看了之后才发现之前其实并不明白。
没看这本书之前我以为我懂 Web 分析,看了之后才发现之前其实并不明白。
算起来,用 AWstats 做了几年的小实验,尽管一些基本的东西是有所了解,但如果要详细说明背后的含义,还是并不清晰。这可能不是我一个人的感受吧? 我遇到过一些做 Web 分析的同仁,整天看网站数据报表,也看不出什么东西来。尽管我们常看到 Web 分析工具的更新,但国内互联网的 Web 分析思路似乎并没有"与时俱进"。 不管承认与否,毕竟是现实一种。
普及这本书,我想能有效避免 Web 分析中的一些误区,以 PageView 为核心的 Web 分析时代应该已经过去。结合自己的实际业务,通过数据去了解客户,真正做点能起到"正反馈"的事儿,而不是到了节假日弄一些无聊活动疯狂弹出一些用户烦透的垃圾页面。这对你们公司也是莫大的损失。
负责网站数据分析的主管啊经理啊总监啊都把这本书偷着买回去仔细读两遍,然后整点靠谱的针对 Web 的 KPI 出来,也让下面的员工心里服气你还算个合格的管理者。把这本书当作了解 Web 的另一面镜子(如果是从传统行业过来的话),通过另一个角度(数据)观察 Web。
此书翻译质量一般...但我想不影响阅读。
Web Analytics,An Hour a Day ,不需那么多,只要一点点。
--EOF--
作者 Avinash Kaushik ,感兴趣的话还可以观看他的相关采访视频。更多信息访问豆瓣上的 精通Web Analytics页面,如果买书直接点击豆瓣上的链接去买吧,也算支持豆瓣了 :)
又及:这本书也被我列入豆列 Web 2.0 网站架构不可或缺的图书。
