前几天在 Blog 里提到答应了 Piner(陈吉平) 要给他的新书《构建 Oracle 高可用环境--企业级高可用数据库架构、实战与经验总结》写篇书评。书是拿到了多日了,断断续续再看,一直没看完。
首先恭喜一下 Piner 的新书终于顺利出版,写一部书本是一件不容易的事情,也一本有质量的书就更难上加难了。也恭喜一下博文视点顺利拿下这本书,装帧质量的确不错,相信读者也会对此满意。记得好几年前 Piner 最早在 CSDN 论坛数据库版灌水,签名经常写着"弱水三千,只取一瓢饮",灌水地移师 ITPub 后没多久我就注意到了这个家伙。那个时候他就经常发一些总结的很好的技术文档(可见写作能力早早就开始培养了),新书的出版也是他厚积薄发的体现。
做 DBA 久了,有时也难免动一动写书的念头,可面对 Thomas Kyte 、Lewis 这些大师的书,真有些"眼前有书写不得,大师图书在上头"的感觉。但是《构建 Oracle 高可用环境》没有作无意义的重复,就内容上,可以说是独辟蹊径。有些章节堪称填补了 Oracle 技术图书的空白,比如第 10 章的 "高可用环境下数据迁移" 与第 16 章的"高可用环境监控架构设计" 都是前人所未能阐述的东西,对很多 DBA 来说,似乎是隔了一层窗户纸,可实际上,能够有功力捅破窗户纸可不是容易的事情,没有足够的经验写不出来,只有经验而没有总览全局怕是也写不出来。
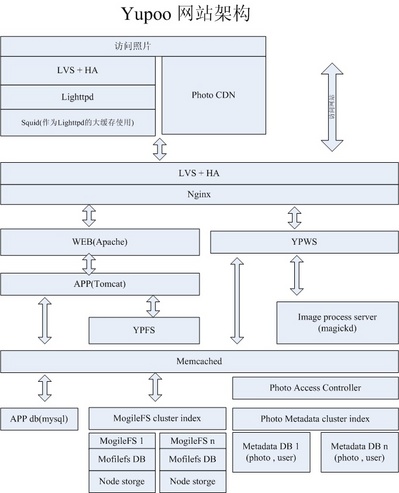
身为国内最大电子商务网站的首席 DBA,"经验总结" 毫无疑问会让无数 DBA 心痒,到底淘宝的数据库是怎么维护的? (我就时不时的去偷师借鉴经验)。不只是 DBA 应该看这本书,架构师、技术经理都应该是这本书的读者。通过本书由点及面的阐述,能够树立一个以 DB 为核心的架构观,进一步理解企业信息技术体系,增强实践技能。
我会向 DBA 推荐本书(建议春节期间就买本回家看)。《构建 Oracle 高可用环境》将会是 2008 年中文图书市场比较重要的一本数据库类图书。
(最后挑个小毛病:建议批量数据更新的处理策略能够用 "Bulk Collect"方法,Piner 似乎一直不喜欢这么用。)
--EOF--