首先思考一个问题:针对弱关系型数据的数据仓库解决方案会是怎样的?
耶鲁大学的这个 HadoopDB 研究项目挺有意思。这是个并行 DBMS(PostgreSQL) 技术和 MapReduce 的结合的产物。
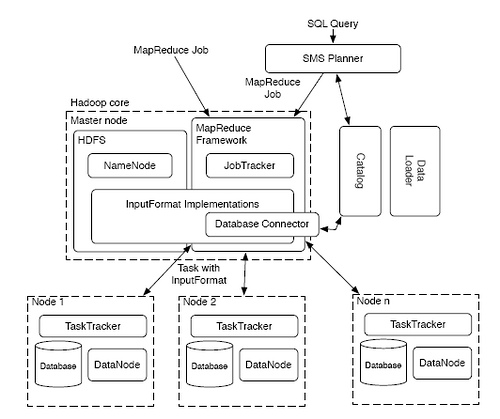
(上图来源)
上图中的 SMS 是 "SQL to MapReduce to SQL" 的缩写。这是 HadoopDB 的一个设计难点。经过了两层转换,对于 SQL 执行的效率多少会是个问题。
也可以对比一下 Facebook 的 Hive :
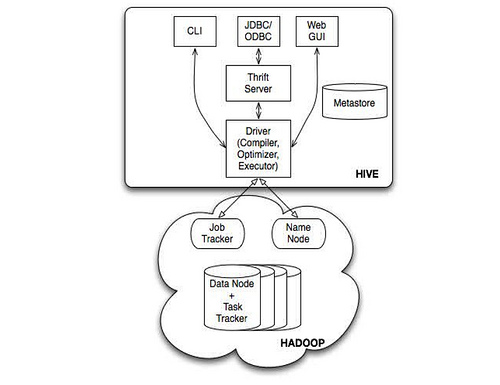
说起 DBMS 和 MapReduce 结合,自然要提起 GreenPlum, 原来是 Hadoop 的间接竞争对手,现在变成直接的了。相比来说,GreenPlum 要更成熟一些。HadoopDB 毕竟是学院派的东西。
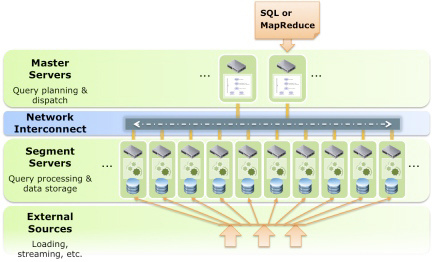
二者都是典型的 Share-Nothing 结构。类似 Oracle 集群的 Share-Storage 的模式现在已经有点过时了。更多混搭出来的技术解决方案让人喜忧参半,喜的是有很多东西可以选择,忧的是你不知道哪个项目生命期更长久。
--EOF--

和greenplum的思路差不多吧
这种DB商用也不怎么看好吧
MPP的节点多了之后
master node的管理成本是几何级数的增加
管理成本 其实未必增加,
要看软件实现的如何
赫赫~
俺的水平也就是mysql的境界啦~~
HadoopDB其实是构建在HIVE上面的,现在没多少代码。
现代的数据库瓶颈多是DiskIO。
Greenplum这样的架构可以支撑到Master节点处理40Gbps。
如果数量处理量超过40Gpbs,现有技术类似Parallel NFS,Lustree,都可以进一步扩展Master的性能。
要按照你这么一说,Parallel NFS,Lustree 还是要比 Greenplum 技术更先进才行呢,可惜不是
分析它的源代码后, 会觉得这只是一个没有前途的实验项目. 首先它的数据hash到各节点是手工做的, 没有parser,没有planner,及optimizer;其次,如果用pg做存储实例,而不用hdfs的datanode,则会失去hdfs的redundancy,这个得自己做,而那paper只字未提;再次, 它没有支持INSERT INTO操作,它只是手工hash数据至各pg节点后, 算出来的结果放到hdfs之上,而不是返回给pg实例的另一张表,这是没有实用价值的;三次,hadoop是一个多人用户环境, 带有调度器去分配资源给各组/用户, hadoopdb这种作法无法做各节点的metrics; 最后它的join假设了要join的两张表,它们的hash key是一致的, 也就是greenplum最理想的状态。Therefore...