针对小型站点的技术普及信息,中大型网站的牛人不用看,耽误您的时间我负不起这责任。
用 Windows 做网站的也别看了,不适合。
说起单点故障(Single Point of Failure,SPOF),倒是可以想起电影 《2012》中,一把焊枪把齿轮卡住,从而导致整个舱门无法关闭,进而整个引擎无法发动。这是个有点生动的例子--如此庞大的一个系统,居然因为一把小小的焊枪而险些毁于一旦。投入巨大人力物力生产的救命方舟居然做不到高可用(High availability),这是致命的事情。
大脑对与人来说,就是一个单点,大脑损坏,人也完蛋;手是不是单点? 一只没了,另一只还能日常生活,从这个角度来说,不是单点。消除单点的最常见的做法:增加冗余。比如,人有两只手。其次,层次化。当然,分层的目的是便于隔离问题。电影 《2012》 中的这个问题,不知道谁是总架构师,看起来,隔离做得不太够 :)
一般来说,只要系统能够比较清楚的分出层次来,要消除单点故障还是有章可循的事情。比如,一个网站,从基础的硬件层,到操作系统层,到数据库层,到应用程序层,再到网络层,都有可能产生单点故障。如果要有效的消除单点故障,最重要的一点是设计的时候要尽量避免引入单点,而随着架构的变化,定期审查系统潜在单点也是有必要的。
有人或许会问,假设一个起步中的站点,只有一台服务器,什么东西都在一个盒子里,到底要怎么做呢? 这里的建议是先抛开主板、CPU 、内存这些,首先必须考虑硬盘(存储层)的问题,如果机器只有一块硬盘,即使你备份计划再完善(不要说你的备份也是备份在这块硬盘上的),还是建议你起码再弄一块。做镜像,让出错的概率降低,这是划算的投入,当然消除单点,成本几乎不可避免的要增加。如果硬盘多,或者有其他备份机制,可选的方法就更多,别刻舟求剑。
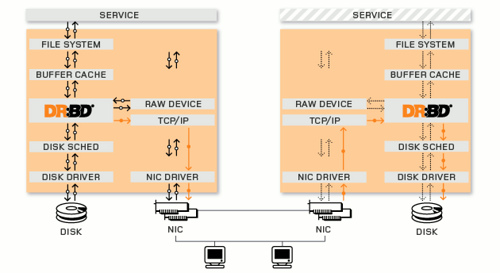
第二个要考虑网卡与网线的单点问题。先说网线,如果要问一个系统里面最容易物理损坏的是哪个组件,答案恐怕非网线莫属,对于网线这样多数时候因为距离需要定制的东西,总是购买成品还是有成本的,从我观察到的情况来看,各个 IDC 的网线使用手工制作的比例不小,这个质量几乎很难控制,一根线,两个水晶头,哪一个出问题都不能正常传输。怎么办? 想办法提升网线整体质量还是弄两根网线放在那里? 解决办法早都有了,网卡绑定 (NIC bonding)一个很简单很通用的办法(refer),但是问题是并非很多人在用。多数 PC 服务器应该都是配置了多块网卡,如果是自己攒服务器,记得网卡多一块成本没多大,但是用处会有很多。如果耐着性子看到这里,先别急着去 Google,还有问题呢,两根网线如何接到上行交换机,什么样的交换机支持绑定,如何确定绑定是真正生效的? 答案是,尝试一下。
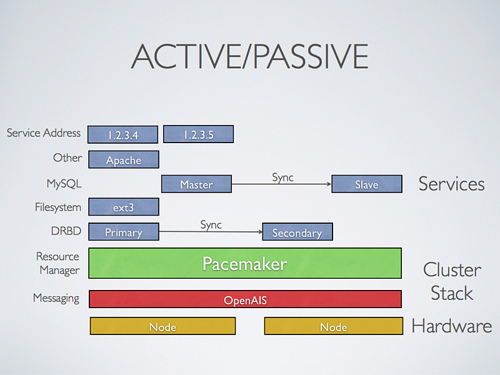
然后是什么? 是跑多个数据库,还是跑两个 Web 服务器,一个不行用另一个顶? 对于单台服务器,其它能消除单点的地方恐怕收效也不会特别大,现在少做无用功,或许要重点考虑如何备份,如何优化,以及出现问题的时候如何做到快速恢复。有一个或许会引起争议的建议是,除了 SSH 登录之外,要不要留一个 Telnet 登录的服务呢? 毕竟 SSH 服务器端守护进程不是百分百靠谱的事儿,如果 IDC 距离较远,需要斟酌一下。好吧,网站有了一点发展,用户量也增加了,感觉需要增加服务器了。再增加一台服务器,抗风险能力一下子加强了许多,毕竟一台机器质量再好,也有出错的时候。现在,Web 服务器、DB 服务器可以考虑引入 HA 的方案,如果单台服务能力够,主备模式也不错。随着网站的发展,服务器数量继续增加...
随着服务器数量的增加,到了必须要自己购买网络设备的时候了。同样的设备,一买恐怕就要买双份,原因无它--一台总要出错,哪怕是电源被拔错--而这样的情况实际上并不少见。如果预算不够,那就再等等,但是要记住,定期审查,有可能的话,进行弥补总不会错。
到现在,所有的服务器都还在一个 IDC 呢,IDC 本身也是个单点啊,服务器被黑怎么办? 机房光线被施工工人挖断怎么办? 机房停电怎么办? 找第二个机房吧。现在选 IDC 首先要考虑什么? 中国特色的互联网问题总要考虑吧,"南北互通"怎么样...或许在选择第一个机房的时候已经遇到了类似的问题,或许现在正在受到这个问题的困扰。选好 IDC 之后,首先计划一下数据如何备份过来,然后,网站的配置信息如何同步或备份过来(这是保证第一个 IDC 出了致命问题之后的最基本的恢复要求)。多个 IDC 之后不得不提上议程的要算 DNS 这个事儿了。你的 DNS 解析商靠谱么? 如果域名提供商遭受攻击,对自己的网站影响能承受么?
更多的服务器,提供更多的应用,更多的用户,更多的收入... 接下来该怎么办呢? 现在,您所面对的已经不是一个小型 Web 站点了,可以不用看这篇文章了。
到现在,我还没说人的问题,如果这些信息只有一个人知道,万一这个人出了点事情怎么办? 作为老板,还要考虑人的单点问题。
--EOF--
Updated: DNS 的健康程度检查重要性应该提升一些。如何检查?有很多在线的工具可供使用,简单直接。