按:此为客座博文系列。投稿人吴朱华曾在IBM中国研究院从事与云计算相关的研究,现在正致力于研究云计算技术。
通过前面两篇介绍,大家应该对Google强大的基础设施有一定的了解。本篇开始介绍构筑在这强大基础设施之上的Google App Engine。
Google App Engine的介绍
由于发布S3和EC2这两个优秀的云服务,使得Amazon已经率先在云计算市场站稳了脚跟,而身为云计算这个浪潮的发起者之一的Google肯定不甘示弱,并在2008年四月份推出了Google App Engine这项PaaS服务,虽然现在无法称其为一个革命性的产品,但肯定是现在市面上最成熟,并且功能最全面的PaaS平台。
Google App Engine 提供一整套开发组件来让用户轻松地在本地构建和调试网络应用,之后能让用户在Google强大的基础设施上部署和运行网络应用程序,并自动根据应用所承受的负载来对应用进行扩展,并免去用户对应用和服务器等的维护工作。同时提供大量的免费额度和灵活的资费标准。在开发语言方面,现支持Java和Python这两种语言,并为这两种语言提供基本相同的功能和API。
功能
在功能上,主要有六个方面:
- 动态网络服务,并提供对常用网络技术的支持,比如SSL等 。
- 持久存储空间,并支持简单的查询和本地事务。
- 能对应用进行自动扩展和负载平衡。
- 一套功能完整的本地开发环境,可以让用户在本机上对App Engine进行开发和调试。
- 支持包括Email和用户认证等多种服务。
- 提供能在指定时间和定期触发事件的计划任务和能实现后台处理的任务队列。
使用流程
整个使用流程主要包括五个步骤:
- 下载SDK和IDE,并在本地搭建开发环境。
- 在本地对应用进行开发和调试。
- 使用GAE自带上传工具来将应用部署到平台上。
- 在管理界面中启动这个应用。
- 利用管理界面来监控整个应用的运行状态和资费。
由于本系列是专注于GAE的实现和设计两方面,所以不会对GAE的使用有非常深入地介绍,如果希望大家对GAE的使用方面有更深的理解,具体可以参看一下GAE的官方文档。
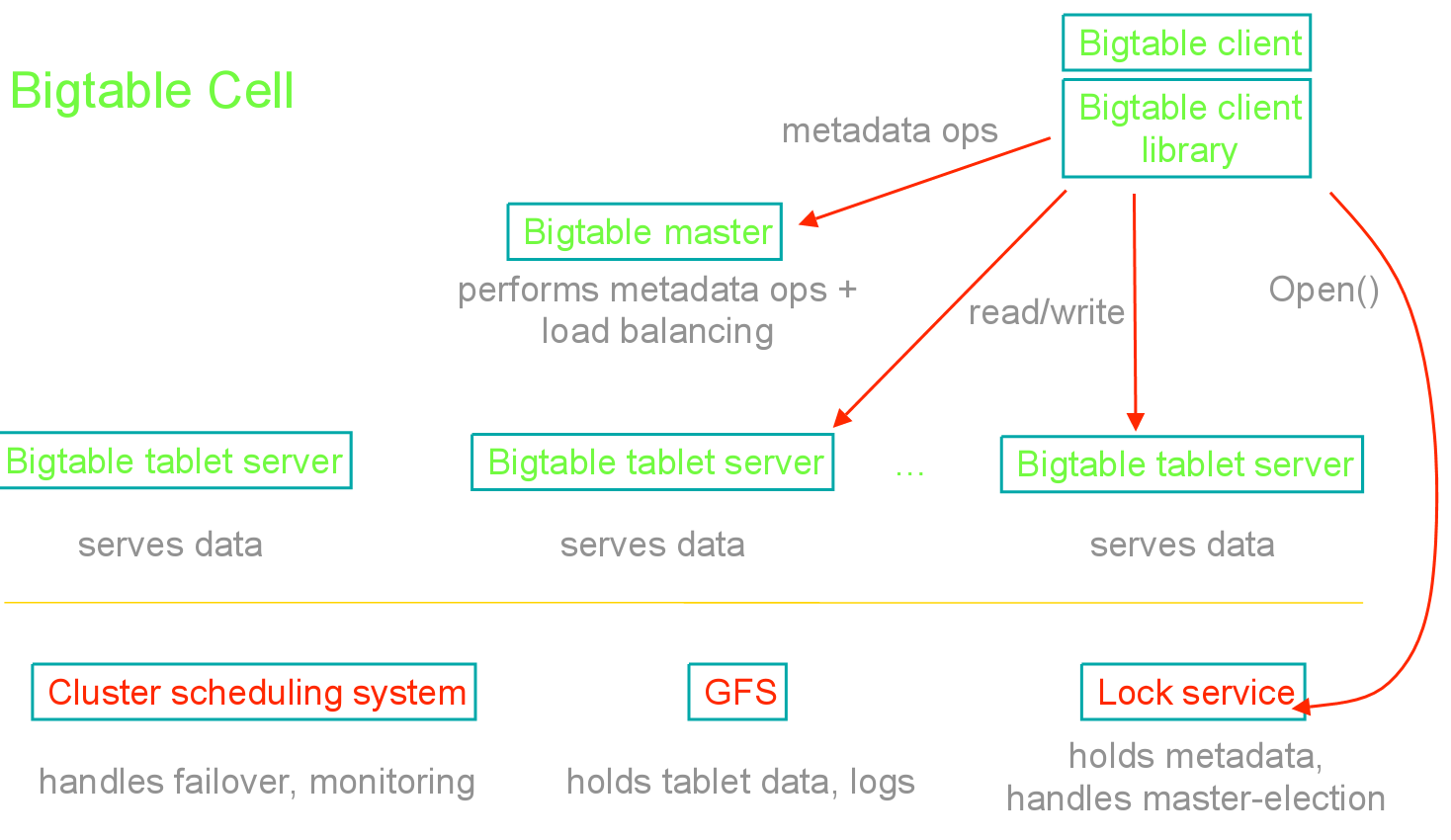
Google App Engine的主要组成部分
主要可分为五部分:
- 应用服务器:主要是用于接收来自于外部的Web请求。
- Datastore:主要用于对信息进行持久化,并基于Google著名的BigTable技术。
- 服务:除了必备的应用服务器和Datastore之外,GAE还自带很多服务来帮助开发者,比如:Memcache,邮件,网页抓取,任务队列,XMPP等。
- 管理界面:主要用于管理应用并监控应用的运行状态,比如,消耗了多少资源,发送了多少邮件和应用运行的日志等。
- 本地开发环境:主要是帮助用户在本地开发和调试基于GAE的应用,包括用于安全调试的沙盒,SDK和IDE插件等工具。
应用服务器
应用服务器依据其支持语言的不同而有不同的实现。
Python的实现
Python版应用服务器的基础就是普通的Python 2.5.2版的Runtime,并考虑在在未来版本中添加对Python 3的支持,但是因为Python 3对Python而言,就好比Java2之于Java1,跨度非常大,所以引入Python3的难度很大。在Web技术方面,支持诸如Django,CherryPy,Pylons和Web2py等Python Web框架,并自带名为"WSGI"的CGI框架。虽然Python版应用服务器是基于标准的Python Runtime,但是为了安全并更好地适应App Engine的整体架构,对运行在应用服务器内的代码设置了很多方面的限制,比如不能加载用C编写Python模块和无法创建Socket等。
Java的实现
在实现方面,Java版应用服务器和Python版基本一致,也是基于标准的Java Web容器,而且选用了轻量级的Jetty技术,并跑在Java 6上。通过这个Web容器不仅能运行常见的Java Web 技术,包括Servlet,JSP,JSTL和GWT等,而且还能跑大多数常用的Java API(App Engine有一个The JRE Class White List来定义那些Java API能在App Engine的环境中被使用)和一些基于JVM的脚本语言,例如JavaScript,Ruby或Scala等,但同样无法创建Socket和Thread,或者对文件进行读写,也不支持一些比较高阶的API和框架,包括JDBC,JSF,Struts 2,RMI,JAX-RPC和Hibernate等。
Datastore
Datastore提供了一整套强大的分布式数据存储和查询服务,并能通过水平扩展来支撑海量的数据。但Datastore并不是传统的关系型数据库,它主要以"Entity"的形式存储数据,一个Entity包括一个Kind(在概念上和数据库的Table比较类似)和一系列属性。
Datastore提供强一致性和乐观(optimistic)同步控制,而在事务方面,则支持本地事务,也就是在只能同一个Entity Group内执行事务。
在接口方面,Python版提供了非常丰富的接口,而且还包括名为GQL的查询语言,而Java版则提供了标准的JDO和JPA这两套API。
而且Google已经在今年的Google I/O大会上宣布将在未来的App Engine for Business套件中包含标准的SQL数据库服务,但现在还不确定这个SQL数据库的实现方式,是基于开源的MySQL技术,还是基于其私有的实现,这是一个问题。
服务
Memcache
Memcache是大中型网站所备的服务,主要用来在内存中存储常用的数据,而App Engine也包含了这个服务。有趣的是App Engine的Memcache也是由Brad Fitzpatrick开发。
URL抓取(Fetch)
App Engine的应用可以通过URL抓取这个服务抓取网上的资源,并可以这个服务来与其他主机进行通信。这样避免了应用在Python和Java环境中无法使用Socket的尴尬。
Email
App Engine应用使用这个服务来利用Gmail的基础设施来发送电子邮件。
计划任务(Cron)
计划服务允许应用在指定时间或按指定间隔执行其设定的任务。这些任务通常称为Cron job。
图形
App Engine 提供了使用专用图像服务来操作图像数据的功能。图像服务可以调整图像大小,旋转、翻转和裁剪图像。它还能够使用预先定义的算法提升图片的质量。
用户认证
App Engine的应用可以依赖Google帐户系统来验证用户。App Engine还将支持OAuth。
XMPP
在App Engine上运行的程序能利用XMPP服务和其他兼容XMPP的IM服务(比如Google Talk)进行通信。
任务队列(Task Queue)
App Engine应用能通过在一个队列插入任务(以Web Hook的形式)来实现后台处理,而且App Engine会根据调度方面的设置来安排这个队列里面的任务执行。
Blobstore
因为Datastore最多支持存储1MB大小的数据对象,所以App Engine推出了Blobstore服务来存储和调用那些大于1MB但小于2G的二进制数据对象。
Mapper
Mapper可以认为就是"Map Reduce"中的Map,也就是能通过Mapper API对大规模的数据进行平行的处理,这些数据可以存储在Datastore或者Blobstore,但这个功能还处于内部开发阶段。
Channel
其实Channel就是我们常说的"Comet",通过Channel API能让应用将内容直接推至用户的浏览器,而不需常见的轮询。
除了Java版的Memcache,Email和URL抓取都是采用标准的API之外,其他服务无论是Java版还是Python版,其API都是私有的,但是提供了丰富和细致的文档来帮助用户使用。
管理界面
用了让用户更好地管理应用,Google提供了一整套完善的管理界面,地址是http://appengine.google.com/ ,而且只需用户的Google帐户就能登录和使用。下图为其截屏:
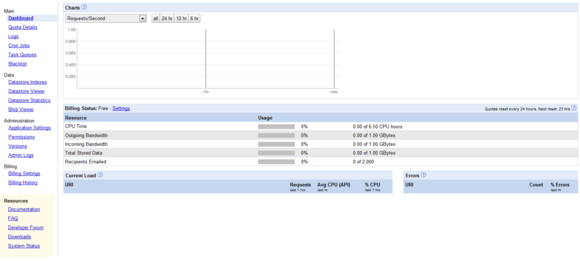 图1. 管理界面(点击看大图)
图1. 管理界面(点击看大图)
使用这个管理界面可执行许多操作,包括创建新的应用程序,为这个应用设置域名,查看与访问数据和错误相关的日志,观察主要资源的使用状况。
本地开发环境
为了安全起见,本地开发环境采用了沙箱(Sandbox)模式,基本上和上面提到的应用服务器的限制差不多,比如无法创建Socket和Thread,也无法对文件进行读写。Python版App Engine SDK是以普通的应用程序的形式发布,本地需要安装相应的Python Runtime,通过命令行方式启动Python版的Sandbox,同时也可以在安装有PyDev插件的Eclipse上启动。Java版App Engine SDK是以Eclispe Plugin形式发布,只要用户在他的Eclipse上安装这个Plugin,用户就能启动本地Java沙箱来开发和调试应用。
编程模型
因为App Engine主要为了支撑Web应用而存在,所以Web层编程模型对于App Engine也是最关键的。App Engine主要使用的Web模型是CGI,CGI全称为"Common Gateway Interface",它的意思非常简单,就是收到一个请求,起一个进程或者线程来处理这个请求,当处理结束后这个进程或者线程自动关闭,之后是不断地重复这个流程。由于CGI这种方式每次处理的时候,都要重新起一个新的进程或者线程,可以说在资源消耗方面还是很厉害的,虽然有线程池(Thread Pool)这样的优化技术。但是由于CGI在架构上的简单性使其成为GAE首选的编程模型,同时由于CGI支持无状态模式,所以也在伸缩性方面非常有优势。而且App Engine的两个语言版本都自带一个CGI框架:在Python平台为WSGI。在Java平台则为经典的Servlet。最近,由于App Engine引入了计划任务和任务队列这两个特性,所以App Engine已经支持计划任务和后台进程这两种编程模型。
限制和资费
首先,谈一下App Engine的使用限制,具体请看下表:
| 类别 |
限制 |
| 每个开发者所拥有的项目 |
10个 |
| 每个项目的文件数 |
1000个 |
| 每个项目代码的大小 |
150MB |
| 每个请求最多执行时间 |
30秒 |
| Blobstore(二进制存储)的大小 |
1GB |
| HTTP Response的大小 |
10MB |
| Datastore中每个对象的大小 |
1MB |
表1. App Engine的使用限制
虽然这些限制对开发者是一种障碍,但对App Engine这样的多租户环境而且却是非常重要的,因为如果一个租户的应用消耗过多的资源的话,将会影响到在临近应用的正常使用,而App Engine上面这些限制就是为了是运行在其平台上面应用能安全地运行着想,避免了一个吞噬资源或恶性的应用影响到临近应用的情况。除了安全的方面考虑之后,还有伸缩的原因,也就是说,当一个应用的所占空间(footprint)处于比较低的状态,比如少于1000个文件和大小低于150MB等,那么能够非常方便地通过复制应用来实现伸缩。
接着,谈一下资费情况,App Engine的资费情况主要有两个特点:其一是免费额度高,现有免费的额度能支撑一个中型网站的运行,且不需付任何费用。其二是资费项目非常细粒度,普通IaaS服务资费,主要就是CPU,内存,硬盘和网络带宽这四项,而App Engine则除了常见的CPU和网络带宽这两项之外,还包括很多应用级别的项目,比如:Datastore API和邮件API的调用次数等。具体资费的机制是这样的:如果用户的应用每天消费的各种资源都低于这个额度,那们用户无需支付任何费用,但是当免费额度被超过的时候,用户就需要为超过的部分付费。因为App Engine整套资费标准比较复杂,所以在这里就主要介绍一下它的免费额度,具体请看下表:
| 类型 |
数量(每天) |
| 邮件API调用 |
7000次 |
| 传出(outbound)带宽 |
10G |
| 传入(inbound)带宽 |
10G |
| CPU时间 |
46个小时 |
| HTTP请求 |
130万次 |
| Datastore API |
1000万次 |
| 存储的数据 |
1G |
| URL抓取的API |
657千次 |
表2. App Engine的免费额度表
从上面免费额度来看,除了存储数据的容量外,其它都是非常强大的。
本篇结束,下篇将对App Engine的架构进行介绍。
--EOF--


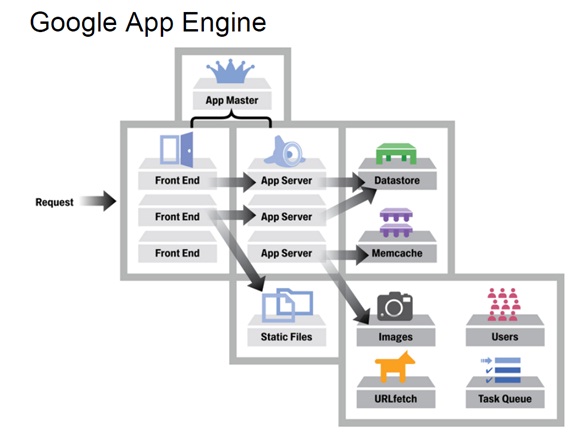
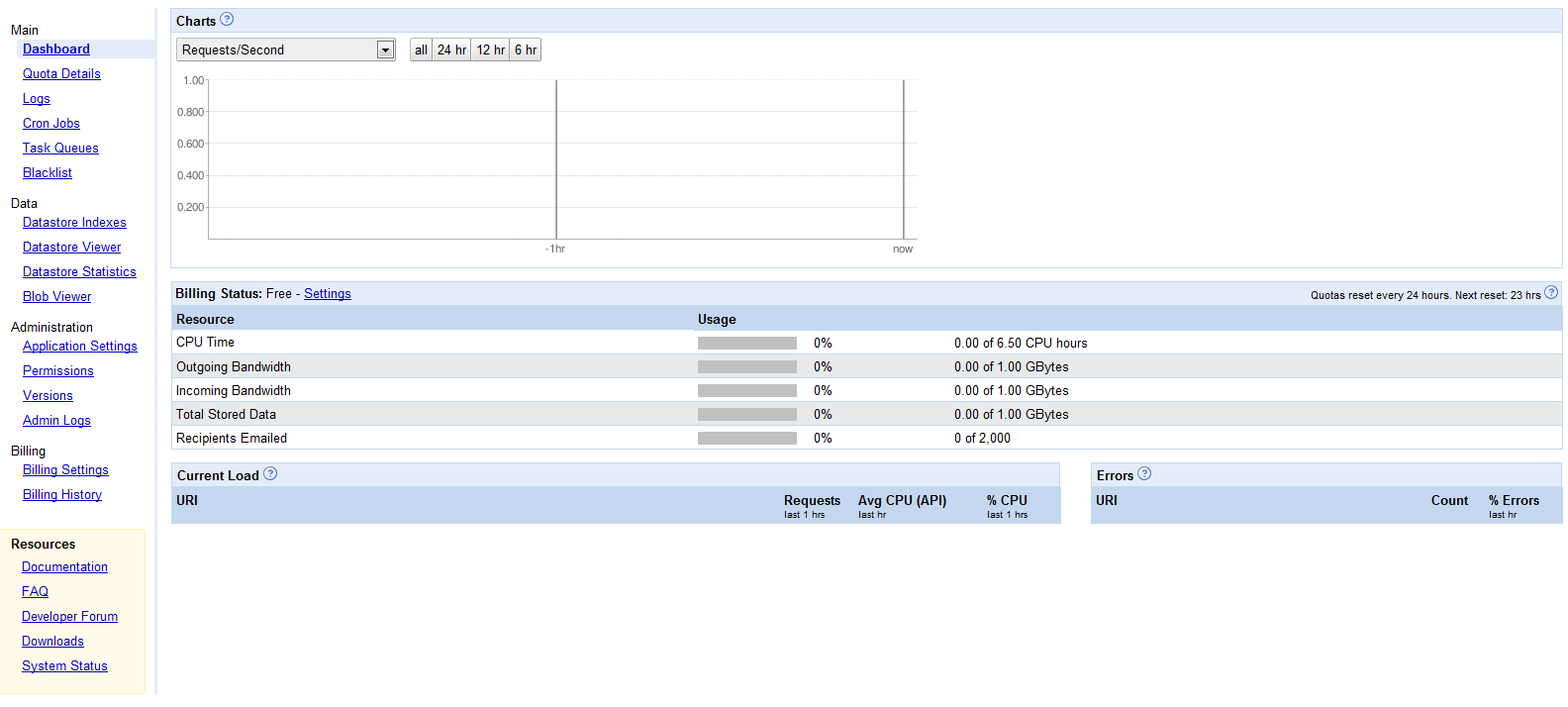
 图1. 2008年Google全球数据中心分布图
图1. 2008年Google全球数据中心分布图