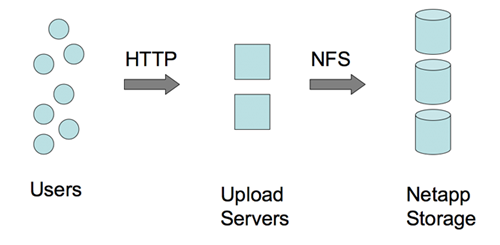
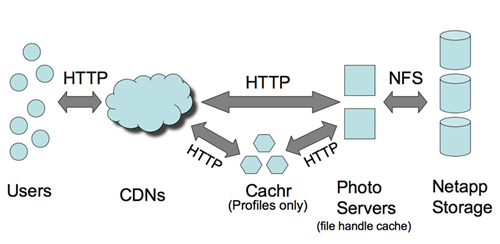
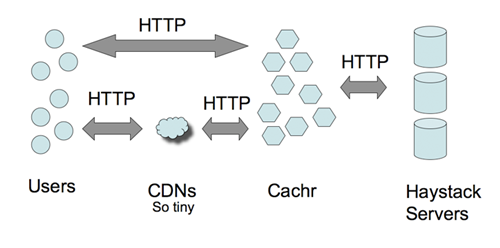
书接上文。视频请访问 InfoQ。
InfoQ中文站: 在 Web 2.0的时代,海量数据对于越来越多的开发者来说,已经不再是一个遥不可及的话题了,可能随便哪一个访问量很大的Web2.0网站都有可能拥有令人咂舌的数据量,那么对于这种网站,除了对数据库存储进行优化,除了缓存,然后还有那些策略?
Fenng: 我觉得可能主要是在存储方面会有一些大的挑战。比如存储的可靠性,像以前就有过 BSP服务商对客户的数据居然没有备份,导致了很多用户损失了一段时间之内的数据,这样总体来说对网站的声誉有很大影响、对用户的体验也很糟糕。
随着互联网的飞速发展,数据总体来说是趋于膨胀性的,在这个过程中,如何把数据有效的存储,并且有效的获取,便是个比较复杂的问题。我们前面说了太多 Web 2.0相关的话题,【换个角度】比如说我所在的公司支付宝,也面临着这样的大数据量、海量数据的挑战。当前我们的一个策略,也是沿袭 SOA 的战略化思想,就是数据库相关的数据服务进行一定的 SOA 化处理。另外一个比较重要的策略就是数据生命周期的管理,我们对这样的,在数据生命周期已经完成后,会对相关的数据做一些归档化的处理,再进行二级存储或者分级存储。那么话说回来,对一些 Web 2.0 网站,我觉得也可以运用这样的思想机制: 对用户已经不大可能访问或者访问频率比较低的(数据),采用分级存储,或者额外做一些访问策略的制订,是很有必要的。
InfoQ中文站: 我们也听说过另外一种分片数据库机制,那么请你谈谈分片这种策略是怎么样一种策略?
Fenng: 分片总的来说,它不是一种比较新的技术, MySQL 在 5 .x 版本之后,有了分区功能。那么在这之前,MySQL 是没有分区功能的。当时如果需要处理一些比较大的数据量,比方说要对根据时间对数据进行历史化处理,就会比较麻烦。人们可能是因地制宜,就产生 Sharding 这样技术策略。
严格来说,数据分片其实在我们以前也有一些相关的实践,在其他(类型)的数据库上,我们也会有一些历史策略,只是当时这个名词没有完全定义下来。据我所知,这个词是从大型在线游戏中发展出来的。大部分用户会集中在某个区域。这一部分集中在某个区域的用户,会把他们放在特定的服务器上。不同区域之间的用户之间的关联度可能不大,这个场景和我们现在的数据库分片策略其实是非常非常相似的,我们当前如果对数据库做一些分片,也会采用这样的基本思想,比如说根据不同的用户 ID 范围,或者说不同的地区(来分片)。
如果建的是商务网站,可能根据产品的类型来做,我们会把不同产品类型的数据扔到不同的 DB上,这些 DB 之间的关联度是很小的。然后我们在 DB 之间,可能会有一个封装层,在这个封装层之上,对应用程序用户来说,就像是透明的,那么就达到了我们数据库上高度扩展化的目标。
InfoQ中文站: 那分片这种策略有什么利弊吗?
Fenng: 首先,分片的好处还是很容易看到的。起码我们的 DB 能达到不依赖于某个单点,而这样能做到平滑的扩展,就像大家常说的 Scale Out (横向扩展)机制。它的弊端也是比较明显,对于事务高速处理这样的网站,它有它的自己的不足之处,事实上好多朋友也应该知道,一个事务如果跨数据库,这样对设计者,对编码人员来说,还是比较棘手的。那么如果一个事务如果跨两个甚至多个 DB,Sharding 复杂度就会很高。Sharding 在业界的应用场景基本上也就是这种读应用比较重的情况,而且对事务的安全性要求不高,这样的场景会非常适合。
【上个月写了篇 Sharding 的东西给《程序员》,还不知道什么时候发表出来】
InfoQ中文站: 目前在许多网站的架构设计中有绝大多数的项目在持久化方面就是采用数据关系映射(ORM)的方式。大家对于这种高负载的大规模网站应用来说,你觉得存在哪些应用呢?
Fenng: 首先一点,我想拿我们支付宝来说,ORM 大家觉得用得非常好。在一个相对比较大的开发环境,对开发团队来说,它的弊端可能就不大容易看出来。因为我们用的是 ORM,就很容易把中间 DB 这层完全隔离出来。然后把这一层的 SQL 处理交给专门的 DB 人员----我们这边还有专门的开发DBA,由他们来专门对这层进行集中的监控管理,乃至一些规划类的工作。这样开发工程师还有架构师这边,他们可以集中精力在其他方面做更多的投入,一个比较大的团队中我觉得像 ORM 这些还是很容易能看到好处的。
【ORM 还有个比较好的地方在于安全性,能有效减少 SQL 注入的隐患】
在另一方面,我们看一下它的弊端,因为像一些 Web 中小网站,可能相对人手也比较少,大家 用的(开发)工具(或框架)呢,可能像 PHP、 ROR 这些东西,也就是在开发上,上手又比较容易的。那么这个时候,事实上一个潜在的问题是,当代码规模到一定程度,如果没有去做一些 ORM,那么可能会给网站带来一些潜在的比如说代码管理上的问题,这一点只是我的个人看法,实际上大家在具体的应用场景可能会有各自头疼的问题,我在这方面不是专家,也仅供大家参考。
InfoQ中文站: 那你所做的支付宝,其实是企业级别的应用,在企业级别应用所采用的这种架构策略和一般 Web 2.0 网站所采用的这种架构策略会有什么异同?
Fenng: 事实上,很明显的一点,支付宝其实业务是非常复杂的【也有一部分人误解支付宝业务很简单】,这和我们很多的Web2.0公司不大一样,Web2.0它可能从一个点切入进去。在这一点上,我觉得做得比较透。支付宝呢,它可能有点像我们以前做的一些通用软件,他要考虑不同的行业、不同的用户、还有像买卖之间,与这么多银行之间的关系等等,这个复杂度还是很大的。
这实际上就从一定程度上决定了我们和 Web 2.0 公司截然不同的应用解决方案,像当前我们在支付宝,在一年之前,甚至两年之前就已经考虑,把我们的整个网站 SOA 化、组件化。在这个过程中,也考虑了一些像 Web 2.0 中的技术元素,但总体的思路呢,还是说向SOA 化,向面向服务这方面大步的跨进,然后就从 SOA 这一点,事实上很多 Web 2.0 公司,他们未必能完全的实现,完全的做到这样的面向服务化,我觉得这可能是两者截然不同的一个表面特点。
另外,像支付宝也在尝试做一些,对外部客户、服务提供一些接口,甚至完全开放的一个平台,这一点又和我们当前这些像 FaceBook ,或者是说,像美国的 MySpace 这样的社交区、SNS 网络了有一些共通之处。
InfoQ中文站: 那目前在 Web 2.0 网站这个领域里面,网站的架构主要有哪些趋势,下边还将有怎么样一个走向呢?
Fenng: 其实作为一个技术人员,每当要谈到趋势,肯定要给大家笑。从中长期来看,国内的一些 Web 2.0 新服务逐渐涌现出来了,随着发展,我相信会有更多的商业化元素加进来。像以前是好多 Web 2.0 公司是完全使用开源的技术,伴随规模扩大化,一些以前提供开源技术的组织或个人他们会尝试进行一些商业化的运作。商业化并不是个坏事情,一方面给我们提供更好的服务。另一方面,他们得到了足够的商业支持,反过来之后他们又会对整体的开源开发环境、发展环境起到很好的促进。我相信在未来的两到三年之内,会有一部分的商业公司涌到 Web 2.0 的发展生态圈里面。
然后从技术方面来讲,像前面几个月 MySQL 被 Sun 收购,起码是在 Web 2.0 这样的软件链条中的一个重要环节(MySQL),有些人可能会感觉出了一些问题。但现在像在数据库这一层呢,也不排除像 PostgresSQL 这些其它的数据库,趁这个机会被商业公司所拥抱,他们也会做出一些更大规模的应用场景出来。在数据库这方面可能会限制大家,几家开源数据库形成一个僵局,Sun 在......这个有些扯远了,还是绕回来。像现在很多的 Web 2.0 公司,他们对 Web 服务器这方面也会采用一些比较新的,像 Nginx, 我觉得在起码在接下来的一段时间内会吸引绝大多数公司长期、大规模的去使用它、去拥抱它,甚至为它开发一些更激动人心的新特性。
【这段时间比较热炒的开放平台、云计算也或许能给我们带来一些思路:很多有技术积累的的公司都有自己打造一套底层的架构的意图,比如针对存储层面向应用的虚拟化等。】
InfoQ中文站: 那最后作为一个由 DBA (Administrator) 成长为DB Architect,同样都是A,但这个A已经有一个变化,那么你对后来者有哪些建议呢?
Fenng: 建议谈不上,跟大家谈谈自己在这个过程中的一些转变。首先从DBA(的角度说),因为 DBA 做一些实际相关的维护工作,从这个过程转到架构师这边,是相对从这比较"实"的岗位转换到现在看起来相对好像稍稍"虚"了一些,但是在这个"虚"的过程中,又相当于我们且退一步,然后就能看得更远一些,能看到整个软件架构的网站发展,甚至是公司战略上的一些事情,这对个人成长是有好处的,我希望大家如果有这个意愿也可以稍微尝试一下,因为 DBA 只是我们整个软件开发行业中的一个环节,那么在这个环节前面和后面,其实都有很多可以做的事情。
其实每个人都不是不可替代的,那我们是否可以尝试一下是否能够去替代别人呢?谢谢大家。
--EOF--